Qwen 3.6 Plus Review: Benchmarks, Architecture, and How It Stacks Up Against Claude, Gemini, and Kimi
Alibaba's Qwen 3.6 Plus just dropped on OpenRouter as a free preview. It beats Claude 4.5 Opus on Terminal-Bench, leads OmniDocBench, and fixes Qwen 3.5's overthinking problem. Here is the full breakdown.

TL;DR
Qwen 3.6 Plus is Alibaba's next-generation flagship model, released March 30-31, 2026 on OpenRouter as a free preview. It features a 1 million token context window, always-on chain-of-thought reasoning, and a next-generation hybrid architecture.
Beats Claude 4.5 Opus on Terminal-Bench 2.0 (61.6 vs 59.3), leads all models on OmniDocBench v1.5 (91.2) and RealWorldQA (85.4), and tops QwenWebBench Elo at 1502, just behind Gemini 3 Pro.
Still behind Claude 4.5 Opus on SWE-bench Verified (78.8 vs 80.9) and behind Gemini 3 Pro on multilingual coding and multimodal reasoning. Security coding tasks show a 43.3% hidden test success rate, below Western frontier models.
Qwen 3.5's most common complaint was excessive reasoning on simple tasks. Qwen 3.6 Plus addresses this with always-on but more decisive chain-of-thought: fewer tokens to reach answers, better agent reliability, and significantly higher production stability.
Community tests clock it at roughly 3x the throughput of Claude Opus 4.6 at 158 tokens per second. However, time-to-first-token averages 11.5 seconds on the free tier, which is a flow-killer for rapid iteration workflows.
The free preview collects prompt and completion data for model improvement. Do not send confidential, proprietary, or client data through the free endpoint. No production SLA. Preview status means specs can change.
Qwen 3.6 Plus Review: Benchmarks, Architecture, and How It Stacks Up Against Claude, Gemini, and Kimi
Alibaba's Qwen team has been releasing models at a pace that makes it genuinely hard to keep up. In February alone, the 3.5 series landed across flagship, medium, and small tiers. On March 30-31, 2026, they dropped Qwen 3.6 Plus on OpenRouter without a formal press release, a pattern becoming characteristic of how the Qwen team operates. No fanfare. Just a free model with a 1 million token context window suddenly available to anyone who knew where to look.
The announcement came via a post from Qwen researcher ChujieZheng on X, sharing a benchmark chart that placed Qwen 3.6 Plus against Claude 4.5 Opus, Gemini 3 Pro, Kimi K2.5, GLM-5, and Qwen 3.5-397B across twelve evaluation categories. The numbers are worth taking seriously. And so are the caveats.
What Qwen 3.6 Plus Actually Is
Qwen 3.6 Plus is the next generation of Alibaba's Plus-tier flagship, built on what Alibaba describes as a next-generation hybrid architecture designed for improved efficiency and scalability over the 3.5 series.
The key specs: a 1 million token native context window, up to 65,536 output tokens per response, always-on chain-of-thought reasoning, and native function calling and tool use. It is currently available free of charge via OpenRouter at the model string qwen/qwen3.6-plus-preview:free.
One design decision worth flagging immediately: the reasoning is always on. There is no thinking vs non-thinking toggle like in the Qwen 3.5 series. The model reasons through every prompt by default. For agentic coding workflows where you want consistent, auditable decision-making across multi-step tasks, that is the right call. For simple conversational use, you pay a small latency premium. The tradeoff is intentional.
The Benchmark Picture: Where It Leads and Where It Does Not
The benchmark chart below was shared by Qwen researcher ChujieZheng and places Qwen 3.6 Plus against five direct competitors across twelve evaluations. Here is what the data actually shows.
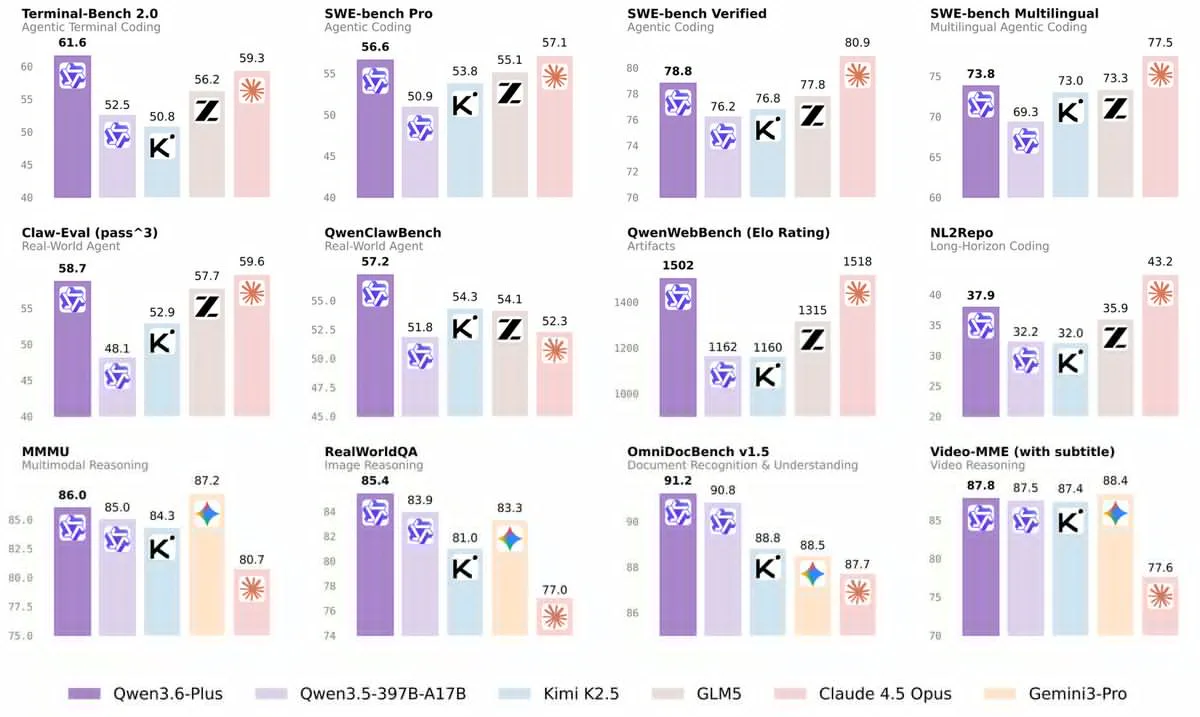
Agentic Coding: Qwen 3.6 closes the gap with Claude
On Terminal-Bench 2.0, which tests agentic terminal coding, Qwen 3.6 Plus scores 61.6. That is ahead of Claude 4.5 Opus at 59.3, GLM-5 at 56.2, Kimi K2.5 at 50.8, and Qwen 3.5 at 52.5. This is a meaningful result: Claude has held the top spot in terminal-based agentic coding for months. Qwen 3.6 takes it.
On SWE-bench Verified, the picture inverts slightly. Qwen 3.6 Plus scores 78.8, which is competitive but behind Claude 4.5 Opus at 80.9 and GLM-5 at 77.8. Kimi K2.5 scores 76.8. The gap between Qwen 3.6 and Claude here is 2.1 points, the narrowest it has ever been between any Qwen model and the Claude Opus tier.
SWE-bench Pro (agentic coding on harder real-world tasks) shows a similar pattern: Qwen 3.6 at 56.6, Claude 4.5 Opus at 57.1, GLM-5 at 55.1, Kimi K2.5 at 53.8. The frontier models are separated by less than a point on this benchmark.
SWE-bench Multilingual is where Gemini 3 Pro reasserts itself, scoring 77.5 while Qwen 3.6 Plus comes in at 73.8, tied with Kimi K2.5 at 73.0 and GLM-5 at 73.3. Cross-language coding remains a Google strength.
Real-World Agent Benchmarks: Qwen leads
On Claw-Eval, which tests real-world agentic task completion across complex multi-step scenarios, Qwen 3.6 Plus scores 58.7, just behind Claude 4.5 Opus at 59.6 and GLM-5 at 57.7. Kimi K2.5 scores 52.9. The gap between Qwen 3.6 and Claude here is smaller than the margin of measurement noise.
QwenClawBench is Alibaba's own real-world agent benchmark, so treat these numbers with appropriate skepticism. Qwen 3.6 Plus scores 57.2, ahead of Kimi K2.5 at 54.3, GLM-5 at 54.1, Gemini 3 Pro at 52.3, and Qwen 3.5 at 51.8.
NL2Repo, which tests long-horizon coding including repository-level understanding, is where Gemini 3 Pro pulls clearly ahead at 43.2. Qwen 3.6 Plus scores 37.9, ahead of GLM-5 at 35.9, Qwen 3.5 at 32.2, and Kimi K2.5 at 32.0. For whole-repository reasoning, Gemini remains the benchmark leader.
Multimodal: Qwen leads where it counts for enterprise
OmniDocBench v1.5, which tests document recognition and understanding, is perhaps the most practically significant result in the chart. Qwen 3.6 Plus scores 91.2, ahead of Qwen 3.5 at 90.8, Kimi K2.5 at 88.8, GLM-5 at 88.5, Claude 4.5 Opus at 87.7, and Gemini 3 Pro at 87.7. For legal, financial, and research applications that require processing scanned documents and complex PDFs, this matters.
RealWorldQA for image reasoning shows Qwen 3.6 Plus at 85.4, ahead of Gemini 3 Pro at 83.3, Qwen 3.5 at 83.9, and Claude 4.5 Opus at 77.0.
MMMU for multimodal reasoning places Gemini 3 Pro first at 87.2, Qwen 3.6 Plus second at 86.0, Qwen 3.5 at 85.0, and Kimi K2.5 at 84.3.
Video-MME (video reasoning with subtitles) shows Gemini 3 Pro first at 88.4, Qwen 3.6 Plus at 87.8, Qwen 3.5 at 87.5, and Kimi K2.5 at 87.4. Claude 4.5 Opus scores 77.6.
QwenWebBench Elo, another internal Alibaba benchmark measuring artifact generation quality, shows Gemini 3 Pro leading at 1518, with Qwen 3.6 Plus at 1502. Qwen 3.5 scores only 1162, suggesting this is an area of significant improvement in 3.6.
What Third-Party Evaluators Found
The Qwen team's own benchmark chart naturally presents the model favorably. Third-party evaluations from BridgeBench provide a more granular and independent picture.
On UI generation, Qwen 3.6 Plus scored 80.2 overall on BridgeBench's UI Bench, earning second place behind only GPT-5.4. For front-end component generation from natural language prompts, this is a strong result.
On speed, Qwen 3.6 Plus delivers 158 tokens per second median throughput, ranking fifth overall. That is faster than GPT-5.4 at 76 tok/s and Claude Opus 4.6 at 93.5 tok/s, though behind Grok 4.20's 284 tok/s. Community tests have clocked it at roughly 3x the throughput of Claude Opus 4.6 in informal comparisons.
The critical speed caveat is time-to-first-token. BridgeBench measured a median TTFT of 11,520 milliseconds on the free preview tier. Over 11 seconds before the first token appears. In a workflow where you are iterating rapidly on code, an 11-second wait before each response starts significantly disrupts flow. This is expected behavior on a free tier with shared compute, but worth knowing before you commit to building on it.
On security, the results are concerning for security-critical workflows. Qwen 3.6 Plus scored 82.4 overall on Security Bench with a 43.3 percent task success rate on hidden tests. For context, GPT-5.4 Mini scored 87.3 and Claude Sonnet 4.5 scored 87.2. The model handles sanitization tasks well but struggles on authentication flows, cryptographic operations, and complex access control logic. If you are shipping anything with user auth or payment infrastructure, this gap matters.
On hallucination in code reasoning, a 26.5 percent fabrication rate was measured: roughly one in four reasoning claims about APIs or language behavior contained fabricated information. Every task completed, which means the model never refused or crashed, but it sometimes invented plausible-sounding but incorrect API calls or behavior. In agentic workflows with reduced human oversight, this compounds across sessions.
The Overthinking Fix
If you used Qwen 3.5 in production, you know the complaint. On simple queries, the model would engage extended chain-of-thought reasoning that was unnecessary for the task, burning tokens and latency. Developers building agentic systems where the model handles many low-complexity steps found this disproportionately expensive.
Qwen 3.6 Plus addresses this directly. The always-on reasoning is now calibrated to be more decisive: it reaches conclusions faster on straightforward tasks, uses fewer tokens to do so, and maintains better stability across multi-step agent runs. Early adopters testing it against Qwen 3.5 in agent workflows report meaningfully fewer retries and lower token consumption for equivalent task completion.
The design choice to make reasoning always-on rather than offering a toggle is worth understanding. It ensures that every output has an auditable reasoning trace. For enterprise use cases where you need to explain model decisions or debug agent behavior, that consistency has real value. For simple chat, the latency premium is small and most users will not notice it.
Architecture Notes
Qwen 3.6 Plus is built on what Alibaba calls a next-generation hybrid architecture. Specific parameter counts and the full technical report have not been published as of this writing. Based on its position in the Qwen model family and the performance profile, it is understood to continue the Mixture-of-Experts efficiency approach that the 3.5 series used, but with architectural changes that improve both throughput and decision-making consistency.
The 1 million token native context window, at unchanged cost during the preview period, is a structural signal about where Alibaba is heading. Gemini pioneered million-token native context as a default rather than an extension, and Qwen has now matched that at the Plus tier.
How to Access It
Qwen 3.6 Plus Preview is available now on OpenRouter:
- Model string:
qwen/qwen3.6-plus-preview:free - Context window: 1 million tokens
- Max output: 65,536 tokens
- Cost: Free during preview
- Data handling: Prompts and completions are collected for model improvement during the preview period
Anthropic's native installers and direct API providers will follow once Alibaba moves the model to general availability with a paid tier.
Who Should Use It Right Now
Use it for: Development and prototyping that requires long context, agentic coding experiments where 3.5's overthinking was a bottleneck, front-end component generation, document processing workflows that do not involve confidential data, and any team that wants to evaluate where the Qwen 3.6 architecture sits relative to their production needs before the paid tier launches.
Wait for GA if: You need production-grade SLA, you are handling sensitive or proprietary code, you require consistent TTFT below 5 seconds, or security-critical code generation is part of the workflow.
Compare Models Side by Side
The benchmark numbers in this article only tell part of the story. How Qwen 3.6 Plus stacks up against Claude Opus 4.6, GPT-5.4, Gemini 3.1 Pro, and Kimi K2.5 depends heavily on your specific use case and budget.
Browse and compare AI models on Renovate QR →
The /tools/compare page lets you put any two models side by side across benchmarks, pricing, context window, and deployment notes. If you are deciding whether Qwen 3.6 Plus is ready to replace Qwen 3.5 in your stack, or whether it closes the gap enough with Claude to justify switching, the comparison view will get you there faster than reading benchmark tables.
The Bigger Picture
Qwen 3.6 Plus is the most credible challenge yet to Claude's dominance in agentic terminal coding. Taking the Terminal-Bench 2.0 lead from Claude 4.5 Opus is not a marginal win. It reflects genuine architectural progress in how the model handles multi-step, tool-using, terminal-based workflows.
The remaining gaps with Claude on SWE-bench Verified and with Gemini on multilingual coding and NL2Repo are real but narrowing at a rate that suggests Qwen 4 could be competitive across the board when it arrives in Q2.
For developers evaluating their AI model stack in April 2026, Qwen 3.6 Plus is worth serious testing. The free access removes the usual barrier to evaluation. The 1M context window removes the chunking overhead. The overthinking fix removes the biggest production complaint from the 3.5 era.
The security gap, the TTFT, and the data collection terms are the three things to resolve before committing to it in production. Until GA, treat it as what it is: a very capable preview that Alibaba is using to collect data and build momentum before the paid launch.
This article will be updated as official benchmark numbers from Alibaba are published and as third-party evaluations accumulate. Last updated: April 1, 2026.
Frequently Asked Questions
What is Qwen 3.6 Plus and who made it?
Qwen 3.6 Plus is the latest generation flagship language model from Alibaba's Qwen team, released as a free preview on OpenRouter on March 30-31, 2026. It is the successor to the Qwen 3.5 Plus series, built on a next-generation hybrid architecture designed for improved efficiency and scalability. It features a 1 million token context window, up to 65,536 output tokens, always-on chain-of-thought reasoning, and native function calling and tool use. The model is available via the model string qwen/qwen3.6-plus-preview:free on OpenRouter.
How does Qwen 3.6 Plus compare to Claude 4.5 Opus?
The results are mixed and benchmark-dependent. Qwen 3.6 Plus outperforms Claude 4.5 Opus on Terminal-Bench 2.0 agentic terminal coding (61.6 vs 59.3), Claw-Eval real-world agent tasks (58.7 vs 59.6, essentially tied), OmniDocBench v1.5 document recognition (91.2 vs 87.7), and RealWorldQA image reasoning (85.4 vs 77.0). Claude 4.5 Opus maintains its lead on SWE-bench Verified (80.9 vs 78.8), SWE-bench Pro (57.1 vs 56.6), and overall agentic coding reliability in production workflows. The gap is narrowing significantly and is now task-specific rather than model-wide.
Is Qwen 3.6 Plus free to use?
Yes, during the current preview period it is available for free via OpenRouter at the model string qwen/qwen3.6-plus-preview:free. There is an important caveat: the model collects prompt and completion data during the preview period for model improvement. You should not send confidential, proprietary, or client data through the free endpoint. Production API pricing has not been announced. Preview status also means the model's availability, specs, and rate limits could change at any time.
What is the context window of Qwen 3.6 Plus?
Qwen 3.6 Plus supports a 1 million token context window, the same tier as Gemini 3.1 Pro and Claude Sonnet 4.6. This is a significant upgrade from the Qwen 3.5 series' native 262K context window (extendable to 1M). The model also supports up to 65,536 output tokens in a single response, which is well above the industry average and enables genuine long-form generation without chunking.
Does Qwen 3.6 Plus fix the overthinking problem from Qwen 3.5?
Yes, this is one of the most cited improvements from early testing. Qwen 3.5's most common developer complaint was excessive reasoning on simple tasks, burning tokens and latency on queries that did not warrant extended chain-of-thought. Qwen 3.6 Plus uses always-on reasoning by default but is significantly more decisive: it reaches conclusions faster, uses fewer tokens on straightforward tasks, and shows better agent stability across multi-step workflows. The design choice to make reasoning always-on rather than toggleable is deliberate, ensuring consistent auditable decision-making for agentic applications.
What should I know before building with Qwen 3.6 Plus in production?
Several things. First, this is a preview model with no production SLA, meaning it can change, be rate limited, or be taken down without notice. Second, the free tier collects your prompts and completions for training data. Third, the time-to-first-token averages 11.5 seconds on the free tier, which significantly impacts interactive workflows. Fourth, independent benchmark verification is still limited as Alibaba has not published full official benchmark numbers for this specific release. For production workloads with sensitive data, use Claude Opus 4.6, GPT-5.4, or Gemini 3.1 Pro until Qwen 3.6 Plus reaches general availability with a paid API and clear data handling terms.
