Kimi K2.6: The Open-Source Model That Ran for 12 Hours Straight and Didn't Break
Moonshot AI released Kimi K2.6 on April 21, 2026. 1 trillion parameters, 300-agent swarms, SWE-Bench Pro above Claude Opus 4.6, and an MIT license. Full technical breakdown, benchmarks, API guide, and what it signals about the open-source AI war.

TL;DR
Kimi K2.6 is Moonshot AI's latest open-source agentic model, released April 21, 2026. 1 trillion parameters, 32B active via MoE, 256K context, Modified MIT License. Available on Hugging Face weights, API, Kimi.com, and Kimi Code CLI from day one.
SWE-Bench Pro: K2.6 scores 58.6, beating GPT-5.4 (57.7), Claude Opus 4.6 (53.4), and Gemini 3.1 Pro (54.2). On HLE-Full with tools it leads every model in the comparison at 54.0. This is the first open-source model to beat GPT-5.4 on SWE-Bench Pro.
K2.6 scales to 300 parallel sub-agents executing 4,000 coordinated steps simultaneously. K2.5 maxed at 100 agents and 1,500 steps. Moonshot demonstrated a 12-hour autonomous Rust optimization run with 4,000+ tool calls. No other model has done this in production.
A research preview feature that opens the agent swarm to external agents from any device, running any model. Humans and AI from different systems collaborate in a shared operational space. This is not a product feature. It is an infrastructure bet on how AI work gets done in 2027.
$0.60 per million input tokens and $2.50 per million output tokens. That is 5x cheaper on input and 6x cheaper on output than Claude Sonnet 4.6. For teams running high-volume agentic coding pipelines, this changes the math significantly.
Moonshot's benchmark numbers are self-reported against their own agent harness. The official SWE-bench leaderboard showed K2.5 at 70.8% under standard tooling vs Moonshot's reported 76.8%. Always run your own evals before committing production workloads.
Kimi K2.6: The Open-Source Model That Ran for 12 Hours Straight and Didn't Break
Most AI releases get announced with a polished blog post and a carefully selected benchmark chart. Moonshot AI released Kimi K2.6 on April 21, 2026, with something more interesting: a demo of the model autonomously optimizing the local inference of Qwen3.5-0.8B using Zig, a niche low-level language, across more than 4,000 tool calls, running continuously for over 12 hours, without human intervention, and finishing with a working result.
I have been following the Kimi model family since K2 launched in July 2025. The trajectory has been one of the most impressive in open-source AI: K2 set a new bar for open agentic models, K2 Thinking extended that with 200 to 300 sequential tool calls, K2.5 added native vision in January 2026 and topped the Artificial Analysis Intelligence Index for open models. K2.6 is not an incremental patch. It is the version where the architecture claims stop being impressive on paper and start being something you can put in production.
Let me walk you through what actually changed and why it matters.
The Architecture: What Is Inside K2.6
Before getting to benchmarks, the technical foundation is worth understanding because it explains the performance profile.
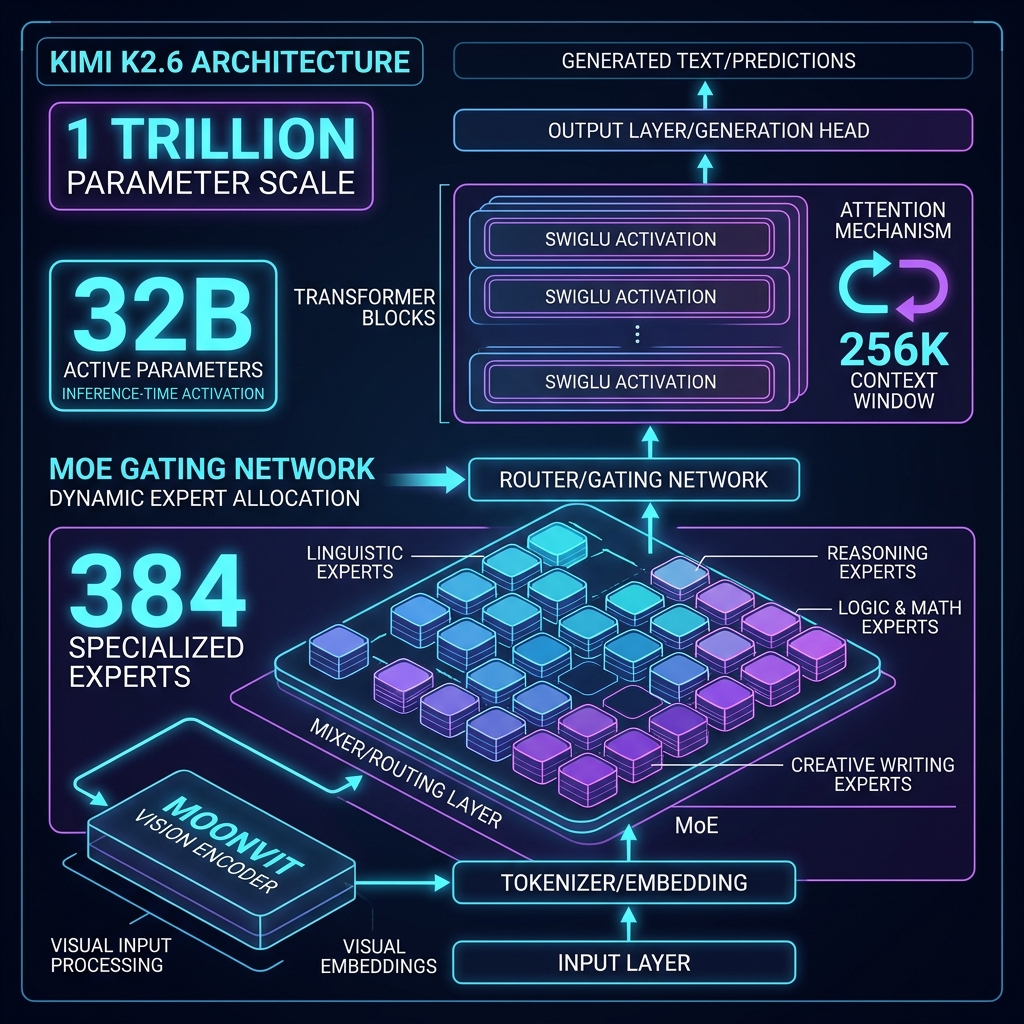 Kimi K2.6 architecture overview. 1T total parameters, 32B active per token via Mixture-of-Experts, 384 experts, MoonViT vision encoder. Source: Moonshot AI model card.
Kimi K2.6 architecture overview. 1T total parameters, 32B active per token via Mixture-of-Experts, 384 experts, MoonViT vision encoder. Source: Moonshot AI model card.
The K2.6 model card lists a 1 trillion-parameter Mixture-of-Experts model with 32 billion active parameters per token, a 256K context window, 384 experts, a MoonViT vision encoder, and a Modified MIT license.
The MoE architecture is the key efficiency insight here. At 1 trillion total parameters, the raw number sounds enormous. But because only 32 billion parameters activate for any given token, the computational cost per inference is closer to a 32B dense model than to a 1T dense model. This is why the API pricing can sit at $0.60/$2.50 per million tokens while delivering frontier-level outputs. You are getting 1T of learned knowledge but paying for 32B of active compute.
Kimi-K2.6 implements an activation function known as the Swish-Gated Linear Unit, or SwiGLU for short. It's more hardware-efficient than earlier algorithms and simplifies the LLM training process in certain respects. The algorithm has been integrated into several other open-source LLM families besides Kimi, most notably Meta's Llama series.
The MoonViT vision encoder enables native multimodal processing: not a vision module added after training, but a unified architecture that processes images and video as first-class inputs. Supported formats include PNG, JPEG, WebP, GIF for images (up to 4K resolution), and MP4, MOV, AVI, WebM for video (up to 2K). Video token cost is calculated dynamically from keyframes, and large files go through the file upload API.
The 256K context window carries over from K2.5. The improvement in K2.6 is not the size but the coherence at that length. Long-horizon tasks were where K2.5 would drift: it could load the context but would gradually lose track of constraints and objectives set hundreds of pages earlier. K2.6 addresses this directly, and the 12-hour Zig demo is the evidence.
The Benchmarks: What the Numbers Actually Say
Kimi K2.6 scores 58.6 on SWE-Bench Pro, compared to 57.7 for GPT-5.4, 53.4 for Claude Opus 4.6, 54.2 for Gemini 3.1 Pro, and 50.7 for Kimi K2.5. On SWE-Bench Verified it scores 80.2. On Terminal-Bench 2.0 it achieves 66.7, compared to 65.4 for both GPT-5.4 and Claude Opus 4.6. On LiveCodeBench v6, it scores 89.6 versus Claude Opus 4.6's 88.8.
 Kimi K2.6 performance vs frontier models. Note the significant lead in agentic coding tasks (SWE-Bench Pro). Source: RenovateQR Data Lab.
Kimi K2.6 performance vs frontier models. Note the significant lead in agentic coding tasks (SWE-Bench Pro). Source: RenovateQR Data Lab.
The story the table tells is nuanced. K2.6 leads on most agentic benchmarks. GPT-5.4 still leads on SWE-Bench Verified. Gemini 3.1 Pro still leads on Terminal-Bench 2.0. To see how these scores translate to specific developer workflows, check our detailed tool review of Kimi or compare it directly against Claude.
Now the honest caveat, and this matters before you route production traffic:
The official SWE-bench leaderboard did not show K2.6 in the fetched results. It did show Kimi K2.5 scoring 70.8 percent under the mini-SWE-agent v2 harness, while Moonshot's own K2.5 table had reported 76.8 percent under its setup. That gap is not scandal. It is a warning label. Agent benchmarks measure the whole harness, not just the model.
Change the agent framework, the retry logic, the timeout rules, or the context handling, and scores shift by 5 to 10 points in either direction. Moonshot's reported numbers are real, but they are measured against Moonshot's own infrastructure. If you are comparing them directly to numbers from other labs measured under different conditions, you are not comparing apples to apples. The only way to know if K2.6 beats Claude Opus 4.7 on your specific codebase is to run your specific codebase through both.
The Real Story: Agent Swarm 2.0
The benchmark table is the doorway. The actual story behind K2.6 is the orchestration layer.
K2.6 pushes Moonshot's Agent Swarm architecture further. The new version supports 300 parallel sub-agents executing across 4,000 coordinated steps simultaneously, up from K2.5's 100 sub-agents and 1,500 steps. The system can decompose complex tasks into heterogeneous subtasks and produce end-to-end deliverables including documents, websites, slides, and spreadsheets within a single run.
Three times the agent count. Nearly three times the step depth. This is not a spec increase: it is a different class of task that becomes possible.
The 12-hour Rust optimization demo that Moonshot ran internally is the clearest demonstration of what this means. The model was given a codebase, a performance target, and access to tools. It then spent 12 hours autonomously making changes, compiling, measuring the results, identifying what worked, discarding what did not, and iterating, all without any human reviewing intermediate steps. At the end, it delivered a working, measurably faster implementation in Zig, a language that is notoriously difficult to work in because the ownership and memory model is strict and unforgiving.
K2.5 could hold a coding task together for a few hundred steps. K2.6 is the version where agentic coding stops being a demo and starts being infrastructure.
 The K2.6 Agent Swarm orchestration layer in action. A central coordinator manages hundreds of specialized sub-agents. Source: RenovateQR Technical Concept.
The K2.6 Agent Swarm orchestration layer in action. A central coordinator manages hundreds of specialized sub-agents. Source: RenovateQR Technical Concept.
For developers building on top of AI coding agents, the practical implication is this: K2.6 can handle tasks that previously required human checkpoints every 30 to 60 minutes. You describe the outcome, set the constraints, and come back when the agent reports completion. That is a qualitatively different development model, not just a faster version of what you were already doing.
The Four Variants: Which One for What
Four variants are available from the model selector: K2.6 Instant for quick responses, K2.6 Thinking for deeper reasoning, K2.6 Agent for research, slides, websites, docs and sheets, and K2.6 Agent Swarm aimed at large-scale search, long-form output and batch tasks.
Here is how I think about when to use each:
K2.6 Instant is your workhorse for chat, code review, quick completions, and any task under 10,000 tokens where latency matters. The reasoning depth of Thinking is wasteful here.
K2.6 Thinking is for the hard problems that benefit from extended chain-of-thought: architecture decisions, complex debugging across multiple files, designing database schemas with non-obvious constraints. If you find yourself writing multi-paragraph prompts explaining edge cases, Thinking is the right variant.
K2.6 Agent is the one that actually generates deliverables: a full website from a description, a slide deck from a brief, a research document from a question. This is the variant Moonshot demos when they show K2.6 building things from scratch. For non-engineers, this is the most immediately practical entry point.
K2.6 Agent Swarm is for the 12-hour Rust jobs. Large-scale parallel research across hundreds of sources. Full-stack application generation from requirements. Any task where the bottleneck is coordination across many parallel work streams. This is not a daily-driver variant for most users. It is the variant that changes what is possible for production engineering teams.
Claw Groups: The Feature That Is Not a Feature Yet
There is something in the K2.6 release that most coverage is treating as a footnote. I think it is the most significant signal in the entire announcement.
Beyond Moonshot's own swarm infrastructure, K2.6 introduces Claw Groups as a research preview, a new feature that opens the agent swarm architecture to an external, heterogeneous ecosystem. The key design principle: multiple agents and humans operate as genuine collaborators in a shared operational space. Users can onboard agents from any device, running any model, each carrying their own specialized toolkits, skills, and persistent memory contexts, whether deployed on local laptops, mobile devices, or cloud instances. At the center of this swarm, K2.6 serves as an adaptive coordinator.
Right now, every major AI agent system is a silo. Your Claude agents talk to Claude. Your GPT agents talk to GPT. Even within the same company, agents built on different models cannot coordinate in real time without significant custom engineering. Claw Groups is an attempt to change the architectural assumption entirely.
The vision is straightforward: you have an agent on your laptop that knows your codebase. Your colleague has an agent on their machine that knows the design system. A cloud agent has access to the production database. Claw Groups lets K2.6 coordinate all three, assigning work based on what each agent knows and has access to, regardless of which model powers each one.
Moonshot's own marketing team reportedly runs end-to-end content production using Claw Groups, with specialized agents for demo creation, benchmarking, social media, and video, all coordinated by K2.6.
This is a research preview, which means it is rough, partially documented, and subject to change. But the direction it points toward is the most interesting long-term infrastructure bet in this release. Treat the 12-hour runs, 300-agent swarms, and context compressor as load-bearing infrastructure, and the shape of K3 becomes visible.
API Integration: How to Get Started
The model is available on day one across multiple access points.
Via the API (recommended for developers):
from openai import OpenAI
client = OpenAI(
api_key="your-moonshot-key",
base_url="https://api.moonshot.ai/v1"
)
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "user", "content": "Refactor this Python module to use async/await throughout"}
]
)
print(response.choices[0].message.content)
With extended thinking enabled:
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "user", "content": "Design the database schema for a multi-tenant SaaS platform"}
],
extra_body={"thinking": {"type": "enabled"}}
)
Via ofox (if you are already using the Moonshot ecosystem):
client = OpenAI(
api_key="your-ofox-key",
base_url="https://api.ofox.ai/v1"
)
response = client.chat.completions.create(
model="moonshotai/kimi-k2.6",
messages=[{"role": "user", "content": "Your prompt here"}]
)
For self-hosting with vLLM:
vllm serve moonshot-ai/kimi-k2.6 \
--tensor-parallel-size 8 \
--max-model-len 262144 \
--quantization int4
The INT4 quantization flag is important for self-hosting: at full precision the model requires significant multi-GPU VRAM, but quantized to INT4 it becomes substantially more deployable on typical enterprise GPU infrastructure.
Pricing reference:
- Input: $0.60 per million tokens
- Output: $2.50 per million tokens
- Cached input: 75 to 83% savings with automatic caching
- Verify current pricing at platform.moonshot.ai before production planning
The Cost Comparison That Matters
For teams making real infrastructure decisions, this table is more important than the benchmarks:
| Model | Input ($/1M tokens) | Output ($/1M tokens) | Notes |
|---|---|---|---|
| Kimi K2.6 | $0.60 | $2.50 | Open weights, self-hostable |
| Claude Sonnet 4.6 | $3.00 | $15.00 | Closed, API only |
| Claude Opus 4.7 | $5.00 | $25.00 | Closed, API only |
| GPT-5.4 | $2.50 | $15.00 | Closed, API only |
| Gemini 3.1 Pro | $2.00 | $12.00 | Closed, API only |
| DeepSeek V3.2 | $0.27 | $1.10 | Open weights |
At 10 million input tokens per day, K2.6 costs $6,000 per month. Claude Sonnet 4.6 at the same volume costs $30,000. Claude Opus 4.7 costs $50,000. That is not a marginal difference. For companies running large-scale agentic pipelines, the economics of this choice compound monthly.
The practical answer for most people: benchmark Kimi Code K2.6 on your actual codebase for two weeks. If the outputs match Claude Sonnet 4.6 quality on your tasks, the 5x cost savings alone justify the switch.
Who K2.6 Is Actually Built For
After reading through all the community feedback and thinking about the architecture, the target user for K2.6 falls into three categories.
Engineering teams running agentic coding pipelines. If you are building with Claude Code, Cursor, or any tool-using coding agent today, K2.6 is worth a direct benchmark comparison on your codebase. The cost differential means that even a 10% quality gap in favor of Claude is worth evaluating carefully against a 5x price difference.
Organizations with data sovereignty requirements. The open weights under Modified MIT mean you can run K2.6 entirely on your own infrastructure. No data leaves your environment. For healthcare, finance, legal, or government teams that cannot use public APIs for sensitive workloads, this is not an alternative. It is the only option at this capability level.
Researchers and teams building multi-agent systems. The 300-agent swarm and Claw Groups research preview represent infrastructure that no closed model offers at any price. If your research involves large-scale agent coordination, K2.6 is the only platform currently offering this as a public API.
What K2.6 Signals About Open-Source AI
Kimi K2.6 is a bet that the next scarce product in AI coding will be the control room: the coordinator that assigns work, tracks failure, moves context between agents, and turns a model into a working software organization.
The conventional narrative about open-source AI has been: open models are cheaper, slightly worse, and useful for teams that need data control. K2.6 breaks that framing. On the benchmarks that matter most for production coding work, it matches or beats the closed frontier. It costs a fraction of the closed alternatives. And it introduces orchestration capabilities that the closed alternatives do not offer at any price point.
Chinese open-source models have already displaced US open models as the developer community's preferred choice on OpenRouter. K2.6's Agent Swarm capabilities give enterprises another reason to build on Kimi rather than wait for GPT or Claude to catch up on openness.
This is the third month in a row that a Chinese open-source model has posted benchmark results competitive with or ahead of the closed Western frontier. DeepSeek V3.2 did it on cost. Qwen 3.6 did it on long-context coherence. Kimi K2.6 is doing it on agentic coding depth and orchestration scale. The pattern is structural, not coincidental.
The Honest Limitations
I want to be direct about what K2.6 is not, because the hype around this release is real and some of it is getting ahead of the evidence.
The benchmark harness caveat. As I covered above, Moonshot's self-reported numbers are measured against their own agent infrastructure. The 5 to 10 point gap between independent and vendor-reported K2.5 benchmarks should calibrate your expectations. Test on your own workloads before trusting any published table.
IDE integration maturity. Kimi Code CLI competes with Claude Code and Aider at the terminal level, but the VS Code and JetBrains extensions are behind Claude's IDE tooling in terms of reliability and feature parity. If tight IDE integration is critical to your workflow, factor this in.
The Claw Groups readiness. The cross-model, cross-device agent coordination is a research preview. It works internally for Moonshot. It is not production-ready for most external teams yet. Treat it as a signal about where Moonshot is headed, not a feature you can build on today.
Self-hosting complexity. The 1T parameter count with INT4 quantization is deployable, but it is not trivial. If you do not have a dedicated ML infrastructure team, the managed API is the practical path for now.
Compare K2.6 Against Other Models
Trying to decide between Kimi K2.6, Claude Opus 4.7, GPT-5.4, and Gemini 3.1 Pro for your specific use case?
Compare AI models side by side on Renovate QR
The /tools directory has benchmark scores, pricing, context windows, and deployment notes for every model covered in this article. We update it as new independent evaluation data arrives, so the K2.6 independent benchmarks will be added as soon as they are published in May 2026.
Last updated: April 21, 2026. Independent third-party benchmarks for K2.6 are expected in May 2026. We will update this article with those results as they are published. Pricing verified against platform.moonshot.ai as of April 21, 2026.
Frequently Asked Questions
What is Kimi K2.6 and when was it released?
Kimi K2.6 is Moonshot AI's latest open-source agentic model, released on April 21, 2026 as a generally available model after a Code Preview beta starting April 13. It is a 1 trillion total parameter Mixture-of-Experts model with 32 billion active parameters per token, 384 experts, a 256K context window, and a MoonViT vision encoder for native image and video understanding. It is available under a Modified MIT License with weights published on Hugging Face, API access through platform.moonshot.ai, and consumer access through Kimi.com and the Kimi App.
How does Kimi K2.6 compare to Claude Opus 4.6 and GPT-5.4?
K2.6 beats both on several key agentic benchmarks. On SWE-Bench Pro it scores 58.6 versus Claude Opus 4.6's 53.4 and GPT-5.4's 57.7. On Humanity's Last Exam with tools (HLE-Full), it leads with 54.0 versus GPT-5.4's 52.1 and Claude Opus 4.6's 53.0. On BrowseComp it scores 83.2 versus GPT-5.4's 82.7. Claude Opus 4.7 and GPT-5.4 retain leads on pure reasoning benchmarks like GPQA Diamond and AIME 2026. The important nuance is that Moonshot's numbers are measured against their own agent harness. Independent third-party benchmark verification has not yet been published.
What is the Kimi K2.6 Agent Swarm and how does it work?
The Agent Swarm is K2.6's multi-agent orchestration architecture, capable of scaling to 300 parallel sub-agents executing 4,000 coordinated steps simultaneously. This is three times the agent count and nearly three times the step capacity of K2.5. K2.6 serves as the adaptive coordinator: it decomposes complex tasks into specialized subtasks, assigns them to agents based on skill profiles, detects failures or stalls, automatically reassigns or regenerates subtasks, and manages the full lifecycle of a multi-agent run from start to finish. The system can produce end-to-end deliverables including code, documents, websites, slides, and spreadsheets within a single autonomous run.
What is Claw Groups in Kimi K2.6?
Claw Groups is a research preview feature that extends the Agent Swarm architecture beyond Moonshot's own agents to an open, heterogeneous ecosystem. It allows users to bring in agents from any device, running any model (not just Kimi), each with their own specialized toolkits and persistent memory contexts. Humans can also participate as collaborators in the same operational space. K2.6 acts as the central coordinator, matching tasks to the best available agent regardless of which model or device it runs on. Moonshot's own marketing team reportedly runs end-to-end content production pipelines using Claw Groups today.
How much does Kimi K2.6 cost via API?
The API is priced at approximately $0.60 per million input tokens and $2.50 per million output tokens. Automatic prompt caching provides 75 to 83 percent cost savings on repeated context. For comparison, Claude Sonnet 4.6 costs $3.00 per million input and $15.00 per million output, making K2.6 five times cheaper on input and six times cheaper on output. For high-volume agentic coding pipelines, this difference is not marginal. At 10 million tokens per day, you are paying $6,000 versus $30,000 monthly. The caveat: "approximately" because Moonshot pricing has changed between releases and should always be verified at platform.moonshot.ai before production planning.
Is Kimi K2.6 open source and can I self-host it?
Yes. Kimi K2.6 is released under a Modified MIT License with weights published on Hugging Face from day one. Self-hosting requires serious infrastructure: at 1 trillion total parameters with a Mixture-of-Experts architecture, you need multiple high-memory GPUs for inference. INT4 quantization is natively supported, which reduces the VRAM requirement significantly, but this is not a model you can run on a single consumer GPU. The practical self-hosting path for most teams is using vLLM or SGLang on a multi-GPU cloud instance, or using a managed inference provider that supports K2.6.
What is the Kimi Code CLI and how does it compare to Claude Code?
Kimi Code CLI is Moonshot's open-source terminal-based coding agent, purpose-built for K2.6. It supports K2.6's thinking modes, tool calling, and multi-step workflows natively. It competes directly with Claude Code and Aider on terminal-based agentic coding tasks. At $0.60/$2.50 per million tokens versus Claude Sonnet 4.6's $3.00/$15.00, the cost argument for Kimi Code is strong if the output quality matches your workload requirements. Moonshot also provides the Kimi Vendor Verifier to confirm third-party deployments are producing correct outputs. The Cursor IDE integration is not as mature as Claude's at this stage, which is worth factoring in if tight IDE tooling matters to your workflow.
What are the four variants of Kimi K2.6?
K2.6 ships in four distinct variants for different use cases. K2.6 Instant is optimized for quick responses on straightforward tasks. K2.6 Thinking provides extended chain-of-thought reasoning for complex multi-step problems. K2.6 Agent handles research, document creation, website generation, slides, and spreadsheets. K2.6 Agent Swarm is the heavyweight variant for large-scale search, long-form output, and batch tasks requiring hundreds of parallel agents. All four are available in the Kimi.com model selector and via API.