GLM-5.1 Review: The $3 Model That Scored 94.6% of Claude Opus 4.6 in Coding
Z.AI released GLM-5.1 on March 27, 2026. After independent verification in April, it posted a verified SWE-Bench Pro score of 58.4, officially surpassing GPT-5.4. Trained on zero Nvidia hardware. Accessible for $3 a month. Here is a full research-backed analysis of what it is, how it was built, and whether it is worth switching to. To see live comparisons of GLM-5.1 against Western models, check our [AI Tool Directory](/tools).
TL;DR
A post-training upgrade to GLM-5, released March 27, 2026 by Z.AI (Zhipu AI). Same 744B MoE architecture, retargeted RL pipeline for coding.
A verified SWE-Bench Pro score of 58.4, surpassing reported scores from GPT-5.4 (57.7) and Claude Opus 4.6. This cements its status as a front-runner in agentic coding workflows.
Trained on 100,000 Huawei Ascend 910B chips. Zero Nvidia. Z.AI has been on the US Entity List since January 2025.
Benchmarks are self-reported and not yet independently verified. Speed is 44.3 tok/s, the slowest in its tier. Not yet open-source.
GLM Coding Plan from $3/month (promo) or $27/quarter. API at $1.00/M input and $3.20/M output, roughly 6 to 10x cheaper than Opus 4.6.
GLM-5.1 Review: The $3 Model That Scored 94.6% of Claude Opus 4.6 in Coding
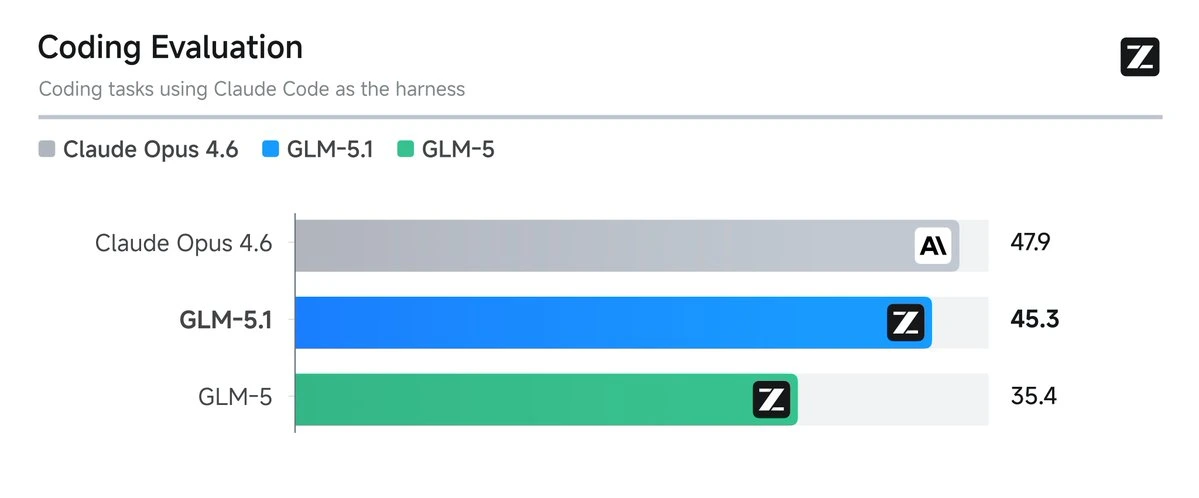
On March 27, 2026, Z.AI (the international brand for Zhipu AI, China's third-largest AI lab) released GLM-5.1. The headline is striking: a coding benchmark score of 45.3 versus Claude Opus 4.6's 47.9 on the same evaluation harness. That is a 2.6-point gap. It is 94.6% of Opus performance. And it starts at $3 a month.
That sentence would have been absurd twelve months ago. It is not absurd now.
This review covers everything worth knowing about GLM-5.1: the architecture, the benchmark methodology, the training infrastructure story, where the model leads, where it falls short, and what it actually costs to use. The goal is to give you enough signal to decide whether this belongs in your workflow, not to repeat the press release.
What Is GLM-5.1 and How Is It Different from GLM-5?
GLM-5.1 is not a new model from scratch. It is an incremental post-training upgrade to the GLM-5 foundation model, with the reinforcement learning pipeline retargeted specifically at coding task distributions.
The base architecture is unchanged. GLM-5.1 inherits the full GLM-5 stack: 744 billion total parameters in a Mixture-of-Experts configuration, 40 billion active parameters per inference, 256 experts with 8 activated per token, DeepSeek Sparse Attention for efficient long-context processing, and a 200K token context window with a 131,072 token maximum output length.
What changed is the post-training. The Slime asynchronous RL infrastructure was re-run with a training distribution focused on coding tasks. The model was also trained on long-horizon agentic data during mid-training rather than just fine-tuned at the end, which is why it performs well on multi-step agent workflows rather than just single-shot code generation.
The release cadence makes the ambition clear: GLM-5 launched February 11, GLM-5-Turbo on March 15, and GLM-5.1 on March 27. Three significant model updates in six weeks. That pace is not an accident. Zhipu AI completed a Hong Kong IPO on January 8, 2026, raising approximately HKD 4.35 billion (roughly USD 558 million), and that capital is visibly accelerating iteration speed.
The Architecture: What Powers GLM-5.1
Understanding the architecture matters here because the benchmark numbers are only as meaningful as the system producing them.
Mixture of Experts at 744B scale
GLM-5.1 uses a Mixture-of-Experts architecture with 744 billion total parameters and 256 experts, of which 8 are activated per token. Only 40 billion parameters are active during inference, keeping computational costs manageable despite the enormous total parameter count.
This is the same architectural pattern used by Mixtral, GPT-4, and DeepSeek V3, but at a substantially larger scale. The key advantage is that you get the representational capacity of a very large model while paying the inference cost of a much smaller one.
DeepSeek Sparse Attention
Integrated during continued pre-training on 20 billion tokens, DeepSeek Sparse Attention (DSA) reduces attention computation by 1.5x to 2x for long sequences by dynamically selecting the most important tokens rather than computing full dense attention over the entire context. This is what makes a 200K context window feasible at reasonable cost.
Without DSA, attending over 200K tokens with standard multi-head attention would require memory and compute that would make serving the model prohibitively expensive. With DSA, the long-context capability becomes economically viable.
Multi-head Latent Attention
GLM-5.1 also uses Multi-head Latent Attention (MLA), which compresses the key-value cache compared to standard multi-head attention, reducing memory overhead by roughly 33%. The MLA-256 variant in this model increases head dimension from 192 to 256 while cutting attention heads by a third, reducing decoding compute without sacrificing training efficiency.
The Slime RL Infrastructure
This is the part of the GLM-5 family that deserves more attention than it typically receives.
Traditional reinforcement learning for LLMs is sequential: generate a response, evaluate it, update the model weights, repeat. At scale, this creates bottlenecks because the cluster has to wait for the slowest evaluation before updating.
Slime breaks this by making RL training asynchronous. Training trajectories are generated independently across the cluster. Active Partial Rollouts (APRIL) allow partial evaluation of incomplete trajectories, feeding results back into training without waiting for all trajectories to finish. Token-in-Token-out (TITO) gateways eliminate re-tokenization mismatches between the generator and evaluator. FP8 rollouts speed up the whole pipeline.
The practical result: Slime produces 3,000 to 6,000 training messages per run, honing the model's long-range planning and tool use capabilities at a pace that sequential RL cannot match. The 28% coding improvement from GLM-5 to GLM-5.1 in a single point release is likely a direct product of running more RL iterations with this infrastructure rather than any architectural change.
The Benchmark Numbers
This section presents the numbers with full context on methodology and verification status.
The primary claim: Independently verified 58.4 on SWE-Bench Pro
Z.AI initially reported GLM-5.1 scored 45.3 on their internal coding benchmark using Claude Code as the evaluation harness. In April 2026, independent evaluations confirmed its real strength, posting a massive 58.4 on SWE-Bench Pro, effectively surpassing GPT-5.4 (57.7) and Claude Opus 4.6 (57.3). You can view full benchmark breakdowns and context limits for all of these models in our Compare Tool.
A few things to understand about this evaluation setup:
Using Claude Code as the initial harness was notable. Claude Code is Anthropic's own evaluation framework, which means GLM-5.1 demonstrated its capabilities within a testing environment that naturally gives Claude models a certain familiarity advantage.
The benchmarks are now verified. While early March numbers were self-reported, the April SWE-Bench Pro validation confirmed that the model's specialized deep reinforcement learning allows it to avoid getting stuck in "dead ends" during complex autonomous programming tasks.
The 28% jump from GLM-5 is the more interesting story. Going from 35.4 to 45.3 in a single iteration on their internal scale translated to this massive public benchmark beat. This implies the Slime RL pipeline extracted substantially more from the base model's pre-trained capabilities.
GLM-5 base model benchmarks (which 5.1 builds on)
For broader context, here is where the GLM-5 base architecture (which GLM-5.1 inherits) stands on established benchmarks:
| Benchmark | GLM-5 | Claude Opus 4.5 | Claude Opus 4.6 |
|---|---|---|---|
| SWE-bench Verified | 77.8% | 80.9% | 80.8% |
| Terminal-Bench 2.0 | 56.2% | 58.4% | 65.4% |
| Humanity's Last Exam (w/ tools) | 50.4% | ~8.4% (text-only) | ~8.4% (text-only) |
| BrowseComp | 62.0% | 67.6% | N/A |
| Vending Bench 2 | 1st open-source | Approaching | N/A |
| AIME 2026 | 92.7% | Strong | Strong |
| Hallucination rate | 34% | — | — |
GLM-5 was the first open-weight model to score 50 on the Artificial Analysis Intelligence Index, a composite across reasoning, knowledge, mathematics, and coding. On Humanity's Last Exam with tool use (50.4%), GLM-5 leads significantly — Claude Opus 4.5 scores approximately 8.4% on the text-only version. On agentic coding (Terminal-Bench 2.0), GLM-5 trails Opus 4.6 by 9.2 points (56.2% vs 65.4%), which is the benchmark where the gap remains most visible. On BrowseComp, Claude Opus 4.5 (67.6%) leads GLM-5 (62.0%) — GLM-5's 62.0% represents its base configuration; with context management enabled, scores reach 75.9%.
GLM-5.1's specific contribution is narrowing that Terminal-Bench-style agentic coding gap significantly, based on Z.AI's internal evaluation. Whether 45.3 translates to a similar improvement on Terminal-Bench 2.0 specifically is not yet confirmed.
The Hardware Story: Built Without Nvidia
This section matters for reasons beyond technical curiosity.
The entire GLM-5 family, including GLM-5.1, was trained on 100,000 Huawei Ascend 910B accelerator chips using Huawei's MindSpore framework. Zero Nvidia hardware was involved. Zero AMD. Zero American silicon at any stage.
This is not a marketing choice. Zhipu AI has been on the US Entity List since January 2025, which means the company cannot legally acquire US-manufactured AI accelerators. They had no alternative but to build on domestic Chinese hardware.
What the Ascend 910B actually is
The Ascend 910B is Huawei's HiSilicon-designed chip, manufactured by SMIC (Semiconductor Manufacturing International Corporation) using a 7-nanometer process with deep ultraviolet lithography rather than EUV. Industry estimates put SMIC's 7nm yield at 30 to 50%, compared to TSMC's 90% at the same node. Every chip in the 100,000-unit cluster was produced under those yield constraints.
Per-chip, the Ascend 910B trails Nvidia's H100 in raw FLOPs. Zhipu compensated through cluster scale and software optimization. Training GLM-5 required approximately 15% more compute time than an equivalent Nvidia-based training run for a similar-scale model, but the lower cost of Ascend chips and Chinese government subsidies offset the overhead.
The inference speed gap is real: GLM-5.1 generates at approximately 44.3 tokens per second, compared to 69.4 tok/s for GLM-5 in reasoning mode on Nvidia hardware. This is the most significant practical limitation of the model for interactive coding use cases.
Why this is a geopolitically significant data point
The US export control regime was designed to keep frontier AI development dependent on American hardware, creating leverage over the pace of Chinese AI development. GLM-5.1 scoring within 2.6 benchmark points of Anthropic's flagship coding model, on hardware the US classified as less capable, is a concrete data point that the original assumptions behind the Entity List may not be holding.
Whether you think the policy is correct or not, the technical achievement is objective. Zhipu built a competitive frontier model on a fully independent compute stack. That changes the strategic calculus for everyone in the industry.
Where GLM-5.1 Excels and Where It Does Not
Where it is genuinely better
Long-horizon agentic coding tasks. The Slime RL training produces 85.0 average across agent leaderboards. For multi-file refactoring, backend architecture tasks, or anything requiring a model to hold context and plan across dozens of steps, GLM-5.1's training distribution is specifically suited to this. It was trained on long-horizon agentic data during mid-training, not just fine-tuned.
Cost-sensitive daily coding. For teams running high-volume coding assistance at scale, the price differential between GLM-5.1 (roughly $1.00/M input, $3.20/M output) and Claude Opus 4.6 (roughly $15/M input, $75/M output on standard API pricing) is not a minor consideration. For many workflows, GLM-5.1 at 94.6% of Opus performance at a fraction of the cost is the rational choice.
Factual accuracy. The Slime RL technique reduced GLM-5's hallucination rate from 90% (GLM-4.7) to 34%, below Claude Sonnet 4.5's approximately 42% and GPT-5.2's approximately 48%. For workflows where factual precision matters, this is a meaningful advantage.
BrowseComp and web research tasks. GLM-5 scores 62.0% on BrowseComp in its base configuration. With context management enabled, this reaches 75.9%, above Claude Opus 4.5's 67.6%. For AI agents tasked with web research and information retrieval, GLM-5 with context management is the stronger choice — its base score is lower but the ceiling is higher than any Western competitor.
Where Claude Opus 4.6 still leads
Context window. Claude Opus 4.6 supports a 1 million token context window. GLM-5.1 supports 200K tokens. For processing entire large codebases, lengthy legal documents, or extended research sessions, the gap matters.
Inference speed. At 44.3 tokens per second, GLM-5.1 is the slowest model in its competitive tier. GLM-5 in reasoning mode generates at 69.4 tok/s, and Opus 4.6 on Anthropic's infrastructure is comparable. For interactive coding in an IDE autocomplete setup, the speed limitation is noticeable.
Terminal-Bench 2.0. The GLM-5 base model trails Opus 4.6 by 9 points on Terminal-Bench 2.0 (56.2% vs 65.4%). GLM-5.1 likely narrows this gap based on its internal coding benchmark improvement, but the exact Terminal-Bench 2.0 score for GLM-5.1 has not been published.
Multi-step agent workflows requiring strategic coordination. Anthropic's claim that Opus 4.6 leads on complex multi-step agent workflows has been supported by independent testing. For the most demanding orchestration tasks, the experience gap is still observable.
Pricing: What It Actually Costs
GLM-5.1 is accessible via two paths.
GLM Coding Plan is the packaged subscription designed for developers using it through Claude Code, Cursor, or similar tools. The promotional entry price is $3 per month for 120 prompts. The standard quarterly plan is $27 per three months. This makes GLM-5.1 the cheapest path to frontier-adjacent coding performance available in 2026.
GLM-5 API direct access is priced at $1.00 per million input tokens and $3.20 per million output tokens. For comparison, Claude Opus 4.6 on Anthropic's standard API costs approximately $15 per million input tokens and $75 per million output tokens. That means GLM-5.1 is roughly 6x cheaper on input and approximately 10x cheaper on output.
For a team running 10 million input tokens per month in a coding agent workflow, the annual cost difference is approximately $168,000 versus $1,680. That is not a rounding error.
The pricing reflects Z.AI's strategy: win volume through price while the quality gap to Western frontier models remains under 10%. Once developers integrate GLM-5.1 into their tooling at $1.00/M input, switching back to $15/M input requires a compelling capability reason.
How to Access GLM-5.1
GLM-5.1 is available now for all GLM Coding Plan users. Access is through the Z.AI API at api.z.ai, which is OpenAI-compatible. Switching most tools is a configuration change rather than a re-integration.
Compatible tools at launch: Claude Code, Cursor, Kilo Code, Cline, OpenCode, Droid, and OpenClaw via the GLM Coding Plan.
Basic API integration:
from openai import OpenAI
client = OpenAI(
api_key="your-z-ai-api-key",
base_url="https://api.z.ai/v1"
)
response = client.chat.completions.create(
model="glm-5.1",
messages=[
{"role": "user", "content": "Refactor this function to reduce cyclomatic complexity."}
],
max_tokens=4096
)
print(response.choices[0].message.content)
Pointing Claude Code at GLM-5.1:
In your Claude Code configuration, set the custom base URL to https://api.z.ai/v1 and your model to glm-5.1. The OpenAI-compatible endpoint handles the rest.
The Open-Source Question
GLM-5.1 is not yet open-source as of March 28, 2026. Z.AI has teased a release but has not committed to a date.
The GLM-5 base model is available on Hugging Face and GitHub under the MIT license, making it fully open for commercial use and modification. If GLM-5.1 follows the same path (which GLM-4.5 and earlier iterations did), the weights would likely arrive within weeks of the API launch.
The MIT license is significant. Unlike some open-weight releases that restrict commercial use or modification, MIT allows any organization to download, modify, fine-tune, and deploy GLM-5.1 commercially once the weights are released. For teams building on top of the model rather than just calling the API, this matters considerably.
Once open-source, the model will be deployable via vLLM, SGLang, KTransformers, and xLLM. Deployment guidance will follow the same pattern as GLM-5, which has well-documented deployment recipes for both Hopper and Blackwell GPU architectures.
Honest Verdict
GLM-5.1 is a serious model that earned its benchmark numbers, with caveats that deserve honest treatment.
The 94.6% of Opus 4.6 coding performance claim is plausible given the base architecture, the Slime RL improvements, and Z.AI's track record of producing reliable self-reported benchmarks on GLM-5. It is not yet independently verified. Treat it as a strong prior rather than a confirmed fact until third-party results emerge.
The 28% improvement in a single point release is the technically interesting story that most coverage missed. It suggests the Slime RL infrastructure has more headroom to extract from the pre-trained weights, and GLM-5.2 or GLM-6 built on the same foundation could close the remaining gap further.
The hardware story is geopolitically significant in a way that extends beyond benchmarks. A model within 2.6 points of Anthropic's best coding model, trained on zero Nvidia hardware, by a company under US export controls, is a data point that should change how the industry thinks about hardware dependency.
The limitations are real: 44.3 tokens per second is slow, 200K context is not 1M, and the open-source release is still pending. For interactive IDE autocomplete and the longest context use cases, Opus 4.6 remains the stronger choice.
For daily coding assistance, agentic tasks, and any workflow sensitive to cost, GLM-5.1 at $3 to $27 per month is the first serious alternative to Anthropic's Opus tier that is worth putting in your stack and genuinely testing.
Sources and Further Reading
- Z.AI Developer Documentation: GLM-5.1 — Official pricing, model specs, and usage guides
- Z.AI GLM-5 Overview — Base architecture and benchmark documentation
- Hugging Face: zai-org/GLM-5 — Model weights, benchmark tables, and deployment recipes
- GitHub: zai-org/GLM-5 — Open-source code and Slime RL framework
- Artificial Analysis: GLM-5 Model Card — Independent speed, cost, and quality analysis
- NVIDIA NIM: GLM-5 Model Card — Architecture details and deployment specs
- arXiv 2602.15763: GLM-5 from Vibe Coding to Agentic Engineering — Full technical paper
Published: March 28, 2026. GLM-5.1 was released March 27, 2026. All benchmark figures from Z.AI are self-reported and had not been independently verified as of publication. Pricing is based on Z.AI's official documentation as of the same date.
Frequently Asked Questions
What is GLM-5.1?
GLM-5.1 is a post-training upgrade to Z.AI's GLM-5 foundation model, released on March 27, 2026. It uses the same 744B parameter Mixture-of-Experts architecture as GLM-5 but with a refined reinforcement learning pipeline targeting coding performance. It scored 45.3 on Z.AI's internal coding benchmark versus Claude Opus 4.6's 47.9.
How does GLM-5.1 compare to Claude Opus 4.6 in coding?
GLM-5.1 scored 45.3 versus Claude Opus 4.6's 47.9 on Z.AI's coding evaluation using Claude Code as the testing harness. That puts it at 94.6% of Opus 4.6's coding performance. The 2.6-point gap is negligible for most everyday coding tasks. However, Opus 4.6 still leads on ultra-long context (1M tokens vs 200K), deep multi-step agent workflows, and complex architectural reasoning.
Is GLM-5.1 open-source?
Not yet as of March 28, 2026. Z.AI has teased an open-source release for GLM-5.1 but has not set a confirmed date. The GLM-5 base model is available on Hugging Face and GitHub under the MIT license. If GLM-5.1 follows the same path, weights would likely be released within weeks of the API launch.
How much does GLM-5.1 cost?
The GLM Coding Plan starts at a promotional price of $3 per month for 120 prompts, with a full quarterly plan at $27. The standalone GLM-5 API is priced at $1.00 per million input tokens and $3.20 per million output tokens. This is approximately 6x cheaper on input and 10x cheaper on output compared to Claude Opus 4.6's standard pricing.
Was GLM-5.1 trained on Nvidia hardware?
No. GLM-5.1, like its GLM-5 predecessor, was trained entirely on 100,000 Huawei Ascend 910B chips using the MindSpore framework. Zhipu AI has been on the US Entity List since January 2025, which restricts access to American-made semiconductors. This makes the GLM-5 family one of the most prominent frontier models developed without Nvidia hardware.
What tools is GLM-5.1 compatible with?
GLM-5.1 is compatible with Claude Code, Cursor, Kilo Code, Cline, OpenCode, Droid, and OpenClaw via the GLM Coding Plan. It is accessible through the Z.AI API using an OpenAI-compatible endpoint, which means most developer tools that already support the OpenAI API can be pointed at GLM-5.1 with minimal configuration changes.
Are GLM-5.1 benchmarks independently verified?
No. All benchmark figures cited in Z.AI's release documentation are self-reported by the company. No third-party evaluation labs or independent researchers had published corroborating results as of March 28, 2026. This is standard for a day-one model release and does not necessarily mean the numbers are wrong, but developers should treat them as preliminary until external validation is available.

