DeepSeek V4 Released: The 1.6 Trillion Parameter Giant Changing the Math of AI
DeepSeek has officially released V4 Pro and V4 Flash. With a 1 million token context window, a revolutionary hybrid attention architecture, and incredibly aggressive API pricing, here is everything you need to know about the April 2026 launch.

TL;DR
DeepSeek V4 officially launched on April 24, 2026. The release includes two models: the 1.6 Trillion parameter V4 Pro flagship and the highly efficient 284 Billion parameter V4 Flash.
Both models now natively support a massive 1 million token context window. By utilizing a new Hybrid Attention architecture, the Pro model processes these massive contexts using only 27 percent of the compute required by the older V3.2 model.
DeepSeek V4 Pro Max ranks as the strongest open-weight model for coding and agentic tasks. It scores an impressive 93.5% on LiveCodeBench and holds its own against top-tier proprietary models like GPT-5.4 and Claude Opus 4.6.
DeepSeek continues to commoditize AI intelligence. V4 Pro API access costs just $1.74 per million input tokens, while V4 Flash costs a mere $0.14 per million input tokens. Context caching drops these prices even further.
DeepSeek V4 Unveiled: The 1.6 Trillion Parameter Giant That Runs on a Fraction of the Compute
The AI industry just received another massive shockwave. On April 24, 2026, Chinese AI startup DeepSeek officially launched its V4 foundation model family. Following the historic success of their V3 and R1 series, the engineering team at DeepSeek has entirely reimagined how large language models handle memory, attention, and compute scaling.
They did not just add more parameters and call it a day. The DeepSeek researchers rebuilt the fundamental architecture of the model to solve the biggest bottleneck in modern AI: the extreme cost of long-context processing.
The result is a pair of open-weight models that boast a colossal one million token context window, natively support complex agentic workflows, and bring unprecedented cost efficiency to the developer market. Here is our comprehensive breakdown of the DeepSeek V4 release, how the new architecture actually works, and how it compares to the heavyweight champions of April 2026.
For a complete overview of available AI coding assistants and their capabilities, visit our AI tools directory.
The Two New Titans: Pro and Flash
DeepSeek split the V4 release into two distinct models designed for very different enterprise needs.
DeepSeek V4 Pro is the absolute flagship. It houses a staggering 1.6 trillion total parameters, making it one of the largest open models ever released. However, thanks to its highly refined Mixture of Experts architecture, it only activates 49 billion parameters per token during generation. It is built to tackle the absolute hardest coding, math, and multi-step reasoning challenges available today.
DeepSeek V4 Flash is the lightweight powerhouse. With 284 billion total parameters and only 13 billion active parameters per token, it is designed for lightning-fast generation speeds and high-volume API workloads. Despite its smaller size, Flash was trained on 32 trillion high-quality tokens and easily outperforms the previous generation's flagship models on general knowledge tasks.
How DeepSeek Broke the Efficiency Barrier
The real story behind V4 is not just the massive parameter count. It is the underlying architecture. To make a one million token context window actually usable without burning through thousands of GPUs, the engineering team had to invent entirely new ways to process data.
Here are the four major technical breakthroughs that make V4 possible.
1. Hybrid Attention Architecture
Standard AI models use dense attention, meaning every single token must mathematically look at every other token in the prompt. This gets exponentially more expensive as the context window grows. DeepSeek V4 solves this by replacing standard attention with a mix of Compressed Sparse Attention and Heavily Compressed Attention.
The model compresses multiple key-value cache entries into single blocks and uses a specialized Lightning Indexer to only pull the relevant information when needed. The efficiency gains are staggering. On a one million token document, DeepSeek V4 Pro uses only 27 percent of the compute and 10 percent of the memory compared to their older V3.2 model.
2. Manifold Constrained Hyper Connections (mHC)
Adding more layers to a neural network usually makes the training process highly unstable. Residual connections tend to break down or amplify errors when you scale past a certain size. DeepSeek introduced a new technique called mHC to force these residual connections onto a safe mathematical manifold. This kept the signal clean and the training completely stable across the massive 61-layer architecture of the Pro model.
3. The Muon Optimizer
Instead of relying on the industry standard AdamW optimizer for the whole network, DeepSeek deployed the newly developed Muon optimizer for the majority of the hidden layers. This unique mathematical approach provided faster convergence during the pre-training phase and successfully prevented random loss spikes, saving the company millions of dollars in wasted compute.
4. Native FP4 Quantization
To fit 1.6 trillion parameters onto standard enterprise hardware, the team baked FP4 quantization directly into the training pipeline. The model essentially learned how to perform perfectly even when its internal weights were compressed to extremely tiny 4-bit precision formats. This drastically reduces the required memory bandwidth for anyone looking to run the model locally.
Three Modes of Thought
Just like Anthropic and OpenAI, DeepSeek realizes that not every user prompt requires a deep philosophical internal monologue. To give developers maximum control over latency and cost, they baked three specific reasoning effort modes directly into the model architecture.
- Non-Think Mode: This mode skips the internal reasoning traces entirely. It provides fast, intuitive responses based on simple rules. It is perfect for routine daily tasks, translation, or summarizing short articles.
- Think High Mode: This triggers conscious logical analysis. It is slower but far more accurate, making it ideal for complex problem solving, coding, and medium-risk business decisions.
- Think Max Mode: This pushes the model to its absolute intellectual limits. It forces the AI to explicitly write out its entire deliberation process, documenting every intermediate step, considered alternative, and rejected hypothesis before returning a final answer. This mode requires a special system prompt and is designed exclusively for the hardest agentic benchmarks.
Benchmark Showdown: DeepSeek vs The World
When you set DeepSeek V4 Pro to its Max reasoning setting, it goes toe to toe with the absolute best proprietary models on the planet.
Here is how the April 2026 leaderboard looks when comparing DeepSeek V4 Pro against GPT-5.4, Claude Opus 4.6, Gemini 3.1 Pro, and the newly released Kimi K2.6. See the full comparison in our AI model comparison tool.
| Benchmark | DeepSeek V4 Pro (Max) | GPT-5.4 (xHigh) | Claude Opus 4.6 (Max) | Gemini 3.1 Pro (High) | Kimi K2.6 (Thinking) |
|---|---|---|---|---|---|
| MMLU-Pro | 87.5% | 87.5% | 89.1% | 91.0% | 87.1% |
| GPQA Diamond | 90.1% | 93.0% | 91.3% | 94.3% | 90.5% |
| LiveCodeBench | 93.5% | N/A | 88.8% | 91.7% | 89.6% |
| SWE-Bench Pro | 55.4% | 57.7% | 57.3% | 54.2% | 58.6% |
| Terminal Bench 2.0 | 67.9% | 75.1% | 65.4% | 68.5% | 66.7% |
Note: Data sourced from independent evaluations and the DeepSeek V4 technical paper published April 24, 2026.
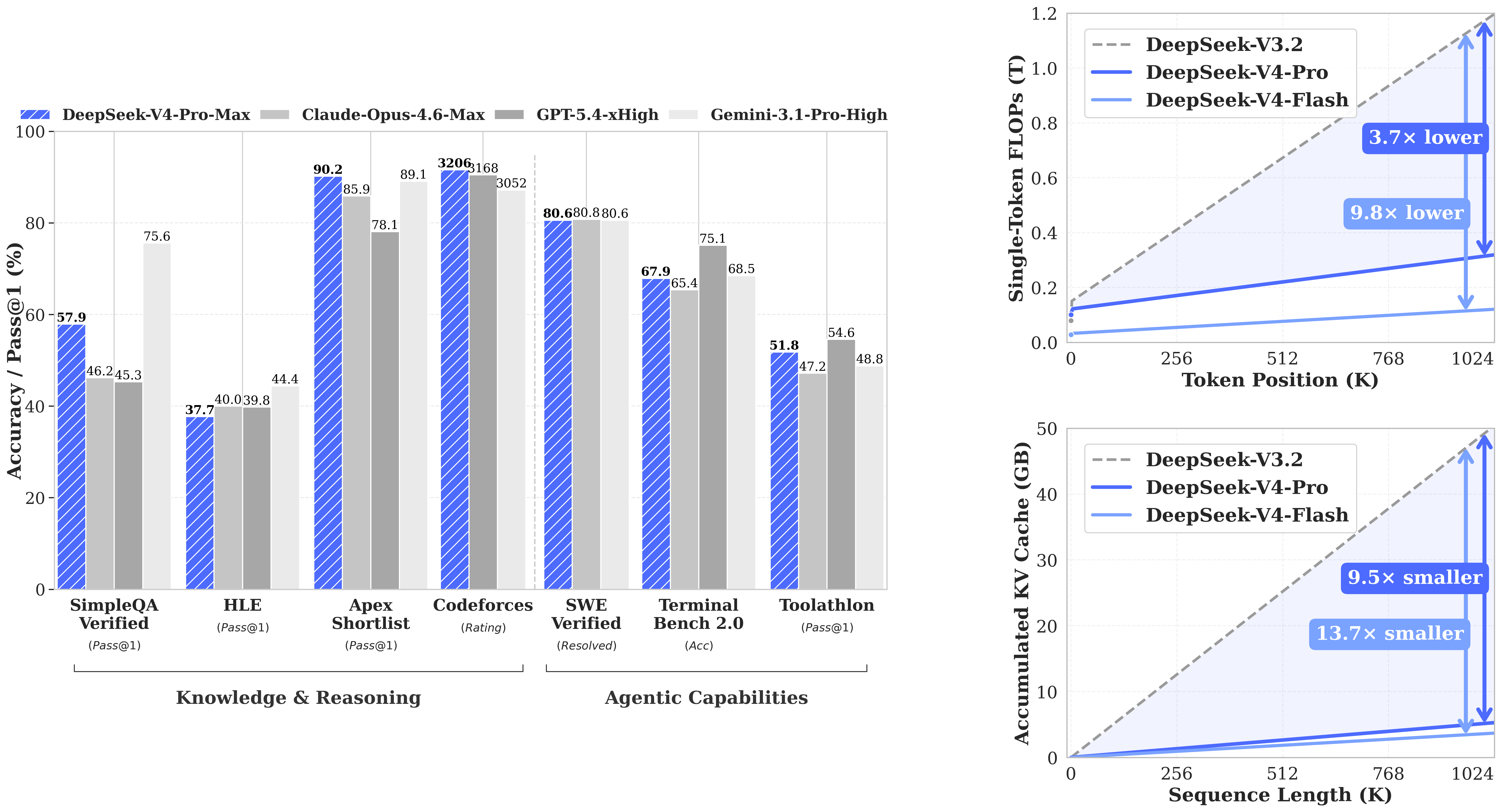
As the data shows, DeepSeek V4 Pro dominates in pure algorithmic coding generation, scoring an incredible 93.5% on LiveCodeBench. While it trails GPT-5.4 slightly on Terminal Bench 2.0 and SWE-Bench Pro, it establishes itself unequivocally as the strongest open-weight model available for software engineering tasks.
Compare DeepSeek V4 against all frontier models side by side →
Real World Capabilities: Moving Beyond the Benchmarks
While synthetic benchmarks are helpful, the DeepSeek team spent heavily on optimizing V4 for real-world enterprise utility.
Agentic Search Mastery: The web search capabilities inside DeepSeek have been entirely overhauled. Instead of relying on basic Retrieval Augmented Generation pipelines, the "Thinking" mode now utilizes a true Agentic Search protocol. The model can iteratively invoke search tools, read the results, realize it needs more context, and execute follow-up queries completely autonomously.
Chinese White-Collar Work: DeepSeek V4 Pro was rigorously evaluated against a suite of 30 advanced professional tasks spanning finance, education, law, and technology. It proactively anticipates implicit user intents, providing supplementary insights and self-verification steps. In human-graded evaluations for Chinese creative and functional writing, V4 Pro achieved a 77.5% win rate in writing quality against Google's Gemini 3.1 Pro.
Pricing: The Ultimate Moat
If the benchmarks prove that DeepSeek belongs in the exact same tier as GPT-5.4 and Claude Opus 4.6, the API pricing is what will actually drive global enterprise adoption. DeepSeek has completely commoditized frontier intelligence.
- DeepSeek V4 Flash: $0.14 per million input tokens and $0.28 per million output tokens.
- DeepSeek V4 Pro: $1.74 per million input tokens and $3.48 per million output tokens.
Furthermore, DeepSeek offers massive discounts for context caching. If your prompt hits their internal cache, the input price for the Pro model drops all the way down to $0.145 per million tokens.
To put this into perspective, OpenAI's newly announced GPT-5.5 charges $5.00 for input and $30.00 for output. Read our full GPT-5.5 review for the complete benchmark breakdown. You can run the DeepSeek V4 Pro flagship model for a fraction of the cost of Western alternatives, making it the undisputed king of return on investment for high-volume data pipelines.
The Verdict
DeepSeek V4 is a masterclass in AI engineering. By completely rethinking the fundamental building blocks of attention and memory, the research team has delivered a 1.6 trillion parameter giant that feels as light and nimble as a much smaller model.
The inclusion of the 1 million token context window, paired with the brilliant Hybrid Attention architecture, opens up entirely new use cases for developers. Whether you are building complex agentic coding swarms, parsing dozens of financial documents simultaneously, or just need an incredibly cheap API for massive data extraction, DeepSeek V4 demands a prominent spot in your technology stack.
Explore all AI coding assistants in our tools directory →
Looking for more AI model comparisons? Check out our blog for the latest reviews and benchmark analyses.
Frequently Asked Questions
What is the difference between DeepSeek V4 Pro and V4 Flash?
DeepSeek V4 Pro is the flagship model equipped with 1.6 trillion total parameters and 49 billion active parameters per token. It is built for complex, agentic reasoning and advanced mathematics. DeepSeek V4 Flash is the lightweight alternative. It has 284 billion total parameters and activates only 13 billion per token, making it perfect for high-volume, low-latency API workloads.
How large is the context window for DeepSeek V4?
Both V4 Pro and V4 Flash support a maximum context window of 1,000,000 tokens. Thanks to the new Compressed Sparse Attention system, the models can search through these massive documents efficiently without hallucinating or running out of memory.
Does DeepSeek V4 beat GPT-5.4 and Claude Opus 4.6?
DeepSeek V4 Pro is highly competitive with the top Western models. When set to its maximum reasoning effort, V4 Pro beats Claude Opus 4.6 on LiveCodeBench (93.5% vs 88.8%) and scores 67.9% on Terminal Bench 2.0. However, it still trails slightly behind Gemini 3.1 Pro on general knowledge benchmarks like GPQA Diamond.
How much does the DeepSeek V4 API cost?
DeepSeek maintains its incredibly disruptive pricing model. V4 Pro costs $1.74 per million input tokens and $3.48 per million output tokens. V4 Flash is priced at $0.14 per million input tokens and $0.28 per million output tokens. If your requests hit the prompt cache, the input costs drop by roughly 90 percent.