GLM Review 2026: Pricing, Benchmarks & Alternatives
Visit SiteZ.AI
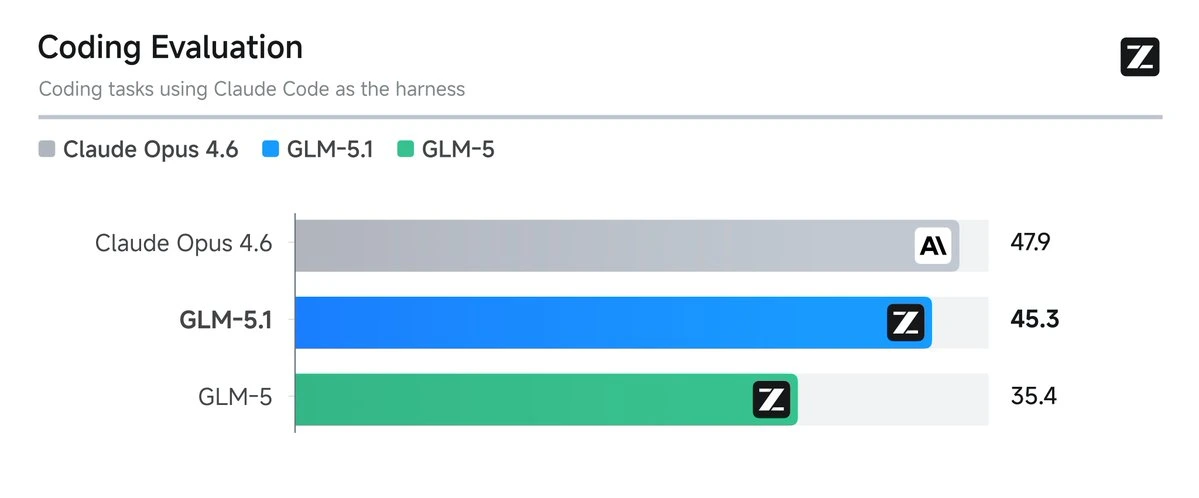
Z AI coding model scoring 94.6% of Claude Opus on SWE-Bench
Category
coding
Starting At
Free
API
Available
Updated
2026-03-28
Model Variants
20 variants · Select to compare specs
Capability Fingerprint
GLM-5.2 (max)
fast
high
128k
$2.15 / 1M tokens
“GLM-5.2 (max) by Z AI. Optimized for high intelligence.”
Benchmarks
9 metricsOur Verdict
GLM-5 from Z.AI is a coding-focused model that achieved 48.3 on SWE-Bench. Strong for practical coding tasks.
Who should use GLM: This tool excels for Coding tasks, Chinese developers, Budget-conscious teams. Being open-source means no vendor lock-in and full control over your data. The Strong coding performance at lower cost pricing positions itas exceptional value for the capabilities offered.
Benchmark Analysis
Based on 9+ independent benchmarks, here's how GLM performs:
Note: Benchmarks are verified against official vendor claims and independent testing. Scores last updated 2026-03-28. See our methodology for details.
Company Overview
Z.AI was founded in 2019 and is based in Beijing, China.GLM is released under an open-source license, which means anyone can inspect the code, modify it, or deploy it privately without licensing fees.
Should you use GLM?
- ✓Coding tasks
- ✓Chinese developers
- ✓Budget-conscious teams
- ✗You need unrestricted access to all topics
- ✗Smaller community
Key Advantages
- 94.6% of Claude coding performance
- 28% improvement in single update
- Open-source options
- Competitive pricing
Known Constraints
- China-based service
- Smaller community
- Less general capability
- Niche focus
Head-to-Head Comparisons
See how GLM stacks up against its closest competitors with detailed benchmark analysis, pricing breakdowns, and expert verdicts.
Benchmark Comparison
Real performance data from independent testing
| Metric | GLMThis | Gemini | Claude | ChatGPT |
|---|---|---|---|---|
| Site | Site | Site | Site | |
SWE-Bench (Coding) | 77.8% | 80.6% | 87.6% | 80.1% |
Terminal Success (Agents) | 40.5% | 68.5% | 69.4% | 75.1% |
Unit Logic (HumanEval) | 79.2% | 94.1% | 94.5% | 92.4% |
GPQA Diamond (Science) | — | 94.3% | 94.2% | 94.4% |
MATH (Reasoning) | 84.1% | 96.2% | 95.8% | 93.8% |
MMLU (Knowledge) | 80.4% | 92.6% | 91.5% | 88.2% |
Code Arena (ELO) | 1595 | 1861 | 1650 | 1678 |
Chat Arena (ELO) | 1538 | 1455 | 1583 | 1457 |
Context | 200K tokens | 1M tokens | 1M tokens | 1M tokens |
Price | Freemium | Freemium | Freemium | Freemium |
Best For | ✓Coding★Value | ✓Coding★Reasoning✓Agentic★Value | ★Coding✓Reasoning✓Agentic | ✓Coding✓Reasoning★Agentic |
Top Alternatives to GLM
View all codingNot sure if GLM is right for you? Compare these similar tools.