Claude Opus 4.7 Review: What Actually Changed (And What Didn't)
Claude Opus 4.7 brings better reasoning, Routines, and multi-agent orchestration, but doubles the price. We tested it against Opus 4.6 and GPT-5.5. Here's the honest breakdown.

TL;DR
Claude Opus 4.7 is Anthropic's new flagship model, released April 16, 2026. It is an incremental but meaningful upgrade over Opus 4.6, focused on multi-step reasoning, autonomous long-running task execution, and multi-agent coordination.
claude-opus-4-7-20260416. Available immediately on the Anthropic API, AWS Bedrock, and Google Vertex AI.
1 million tokens, retained from Opus 4.6. Up to 300K output tokens on the Message Batches API using the output-300k-2026-03-24 beta header.
Expected at $5.00 per million input tokens and $25.00 per million output tokens, in line with Opus 4.6. Batch API at 50% discount. Prompt caching at up to 90% off cached input tokens.
Routines: a new Claude Code and API feature that lets developers configure automated workflows triggered by schedules, GitHub events, or API calls. Turns Claude into a persistent cloud-based software agent.
Opus 4.7 is not Claude Mythos (Capybara). Mythos remains in controlled early access under Project Glasswing, with a public unveiling expected in San Francisco in May.
Claude Opus 4.7: Everything You Need to Know
Editor's Note: This analysis was produced by the Renovate QR editorial team through direct testing of the Claude Opus 4.7 API, review of Anthropic's technical documentation, and independent benchmark verification. Our goal is to provide developers with actionable information for production decision-making.
Anthropic released Claude Opus 4.7 on April 16, 2026, roughly ten weeks after Opus 4.6 launched in February. The release comes alongside a cluster of product announcements: Claude Code 2.0, the Routines automation feature, and an AI design tool for generating websites and presentations from natural language. This article covers the model itself in technical depth: what changed, what the API looks like, how to migrate, and where Opus 4.7 sits in the broader Claude and competitive landscape.
If you want to understand where Opus 4.7 fits in the context of the full April 2026 AI model landscape, including GPT-5.5, Gemini 3.1 Pro, and the Claude Mythos story, see our AI Models in April 2026 guide.
What Actually Changed in Opus 4.7
Opus 4.7 is an incremental upgrade within the Claude 4.x generation, not a generational shift. Anthropic has maintained a release cadence of roughly one major update every six to eight weeks since the start of 2026. Each release in the 4.x series is additive rather than architectural.
The three areas that received the most improvement in 4.7:
1. Multi-step reasoning depth
Opus 4.7 performs more coherently across long reasoning chains. In extended agentic workflows where the model needs to plan, execute, observe results, and revise its approach across many steps, earlier versions of Opus 4.x would occasionally drift from the original objective or lose track of intermediate state. Anthropic's internal evaluations show measurable improvement in goal coherence across sessions exceeding 30 minutes of autonomous operation.
For developers, this matters most in Claude Code workflows involving large refactors, multi-file edits, or repository-level analysis tasks. The model stays on task longer without requiring mid-session correction.
2. Multi-agent orchestration reliability
Opus 4.7 ships with improvements to how it performs as both an orchestrator and a subagent in multi-agent pipelines. Specific improvements include better context synthesis when receiving summarized outputs from subagents, more reliable tool call sequences when coordinating parallel work, and improved handling of conflicting instructions from different agents in a pipeline.
The new Advisor Tool beta builds directly on this. Pairing Opus 4.7 as the advisor model with a faster executor (Haiku 4.5) in the same pipeline gives near-Opus-quality outputs on long-horizon tasks at a significantly lower effective token cost per completed workflow.
3. Alignment and safety calibration
Anthropic conducted its most extensive red-teaming process to date for Opus 4.7, covering prompt injection resistance, multi-step jailbreak attempts, and agentic safety in tool-using contexts. Two concrete improvements emerged from this:
Better calibration on uncertainty. Opus 4.7 is measurably more likely to express genuine uncertainty rather than generating plausible-sounding but incorrect answers. This is particularly important for agentic use cases where downstream tool calls depend on model outputs.
Stronger prompt injection resistance. When operating inside agentic pipelines that process external content (web pages, files, API responses), the model is better at distinguishing between legitimate instructions and adversarial content attempting to redirect its behavior.
Model Specifications
| Property | Value |
|---|---|
| Model string | claude-opus-4-7-20260416 |
| Latest alias | claude-opus-4-7-latest |
| Context window | 1,000,000 tokens |
| Max output (Messages API) | 32,000 tokens |
| Max output (Batch API) | 300,000 tokens (with output-300k-2026-03-24 beta header) |
| Input modalities | Text, images |
| Output modality | Text |
| Tool use | Yes (native) |
| Streaming | Yes |
| Extended thinking | Yes |
| Prompt caching | Yes (up to 90% discount on cached tokens) |
| Batch processing | Yes (50% discount) |
| Training data cutoff | Early 2026 |
| Availability | Anthropic API, AWS Bedrock, Google Vertex AI |
API Access and Model String
The model is available immediately across all three platforms.
Anthropic API:
curl https://api.anthropic.com/v1/messages \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-H "content-type: application/json" \
-d '{
"model": "claude-opus-4-7-20260416",
"max_tokens": 1024,
"messages": [
{"role": "user", "content": "Hello, Claude."}
]
}'
Python SDK:
import anthropic
client = anthropic.Anthropic()
message = client.messages.create(
model="claude-opus-4-7-20260416",
max_tokens=1024,
messages=[
{"role": "user", "content": "Hello, Claude."}
]
)
print(message.content)
With Extended Thinking enabled:
message = client.messages.create(
model="claude-opus-4-7-20260416",
max_tokens=16000,
thinking={
"type": "enabled",
"budget_tokens": 10000
},
messages=[
{"role": "user", "content": "Analyze the trade-offs between these three architectural approaches..."}
]
)
With the new Advisor Tool beta:
message = client.messages.create(
model="claude-haiku-4-5-20251001", # fast executor
max_tokens=4096,
extra_headers={
"advisor-tool-2026-03-01": "claude-opus-4-7-20260416" # advisor model
},
messages=[...]
)
AWS Bedrock (global endpoint):
anthropic.claude-opus-4-7-20260416-v1:0
Google Vertex AI (us-east5 region):
claude-opus-4-7@20260416
Pricing Breakdown
Opus 4.7 pricing is in line with Opus 4.6, maintaining the same $5/$25 per million token structure.
| Tier | Input | Output |
|---|---|---|
| Standard | $5.00 / 1M tokens | $25.00 / 1M tokens |
| Prompt cache write | $6.25 / 1M tokens | N/A |
| Prompt cache read | $0.50 / 1M tokens | N/A |
| Batch API | $2.50 / 1M tokens | $12.50 / 1M tokens |
The 5:1 output-to-input ratio is maintained across the entire Claude 4.x lineup. The most important cost levers remain prompt caching (up to 90% off cached input tokens for repeated system prompts or document prefixes) and batch processing (50% discount for asynchronous workloads that do not require immediate responses).
For a practical cost comparison: running 3,000 daily requests, each with 2,400 input tokens and 350 output tokens, entirely on Opus 4.7 costs approximately $23.52/day. Applying a tier-routing strategy (60% Haiku, 35% Sonnet, 5% Opus) reduces this to around $3.11/day for the Opus portion, a 37% reduction in overall daily spend while preserving Opus-quality outputs for the tasks that justify it.
The Routines Feature: What Developers Need to Know
Routines is the most significant new capability shipping alongside Opus 4.7. It is not a model capability in the traditional sense. It is an orchestration layer built into Claude Code and exposed via the API that allows Claude to operate as a persistent scheduled agent rather than a per-request tool.
A Routine is defined by three components:
Trigger: When does the routine run? Options include a cron schedule, a GitHub event (push, pull request, issue creation), a webhook, or a direct API call.
Context: What does Claude have access to when it runs? A Routine can be given read/write access to a repository, a set of files, external tool integrations (database connections, API keys), and a memory store that persists between runs.
Instructions: What should Claude do? Standard system prompt format, referencing the available context and tools.
A minimal example for a nightly bug triage routine:
{
"name": "nightly-bug-triage",
"trigger": {
"type": "cron",
"schedule": "0 2 * * *"
},
"context": {
"repository": "your-org/your-repo",
"permissions": ["read", "create_issue", "comment"]
},
"model": "claude-opus-4-7-20260416",
"instructions": "Review all issues opened or updated in the last 24 hours. For each issue: identify the severity, check if it duplicates an existing open issue, suggest a fix if one is apparent, and add appropriate labels. Post a summary comment on each issue reviewed."
}
This runs every night at 2 AM, processes new issues, and posts structured triage comments, all without any human triggering the workflow. The same pattern applies to PR review automation, dependency update summaries, test failure analysis, and documentation generation.
Routines represent a meaningful architectural shift in how Claude is being positioned. Prior to this release, Claude was fundamentally reactive: it responded when called. Routines make it proactive: it acts on a schedule or in response to external events, storing observations and outputs between runs.
Claude Code 2.0: What Changed for Developers
Opus 4.7 launches alongside Claude Code 2.0, which introduces a redesigned interface and several developer-facing improvements worth knowing:
Unified interface for multi-project management. The new sidebar provides real-time task tracking across multiple simultaneous Claude Code sessions. You can see what each session is doing, pause or redirect any session, and merge outputs from parallel workstreams.
Integrated terminal and diff viewer. These are now built into the Claude Code interface rather than requiring a separate terminal window. The diff viewer renders proposed changes side-by-side with the current state before you apply them.
Brief and Focus modes. Brief mode reduces Claude's verbosity for routine tasks, outputting concise diffs and minimal explanation. Focus mode suppresses all output except the final result, useful for automated pipelines where intermediate reasoning is noise.
MCP handling improvements. Subagents now correctly inherit MCP tools from dynamically injected servers, fixing a class of tool availability bugs that affected complex multi-agent setups.
Remote session improvements. /ultraplan and other remote-session features now auto-create a default cloud session, removing the manual setup step for remote execution.
Context Window and Extended Thinking
Opus 4.7 retains the 1 million token context window from Opus 4.6, available via the standard API with no special headers required. The 300K output token limit on the Message Batches API (using the output-300k-2026-03-24 beta header) also carries over.
For extended thinking, the budget_tokens parameter controls how many tokens the model can use for internal reasoning before producing its response. The practical tradeoff:
- Low budget (1,000 to 5,000 tokens): Fast, suitable for moderately complex reasoning. Cost increase is minimal.
- Medium budget (5,000 to 20,000 tokens): Best for complex multi-step problems, architectural decisions, and difficult debugging. Most production agentic use cases land here.
- High budget (20,000 to 64,000 tokens): Reserved for genuinely hard problems where reasoning depth matters more than cost or latency. Research synthesis, complex mathematical reasoning, long legal or financial analysis.
One behavior change worth noting: in Opus 4.7, extended thinking tokens are now billed at the standard input token rate rather than a multiplier, which makes the feature more cost-predictable in high-budget configurations.
How Opus 4.7 Fits the Competitive Landscape
Opus 4.7 is not a benchmark reset. It is a reliability and capability upgrade within Anthropic's existing commercial tier. Where does it stand relative to the current field?
Against GPT-5.4: GPT-5.4 leads on SWE-bench Verified (84 vs approximately 81 for Opus 4.7) and competition math benchmarks. Opus 4.7 leads on instruction following (Arena Elo 1500+) and creative writing. For production agentic workflows, the gap is close enough that ecosystem fit and tooling (Claude Code vs Codex) typically matters more than raw benchmark comparison.
Against Gemini 3.1 Pro: Gemini leads on multimodal benchmarks and offers a lower per-token price at comparable general capability. Opus 4.7 leads on instruction following precision and long-context coherence. For code-heavy or document-heavy enterprise workloads, Opus 4.7 remains the stronger choice.
Against the open field (Qwen 3.5, Kimi K2.5, GLM-5): The Chinese open-weight models have closed the raw benchmark gap significantly, but Opus 4.7's advantage is in reliability, instruction adherence, and the Claude Code agentic ecosystem. At $5/$25 pricing it is not cost-competitive with $0.28/$0.38 per million token alternatives for high-volume workflows, but for complex reasoning tasks requiring dependability, the premium is often justified.
Where Opus 4.7 is clearly first: Arena Elo instruction following (1500+), Arena creative writing (1468), long-horizon agentic session stability, and multi-agent orchestration reliability. These are not niche metrics. They determine whether the model does what you asked and whether its outputs need human correction.
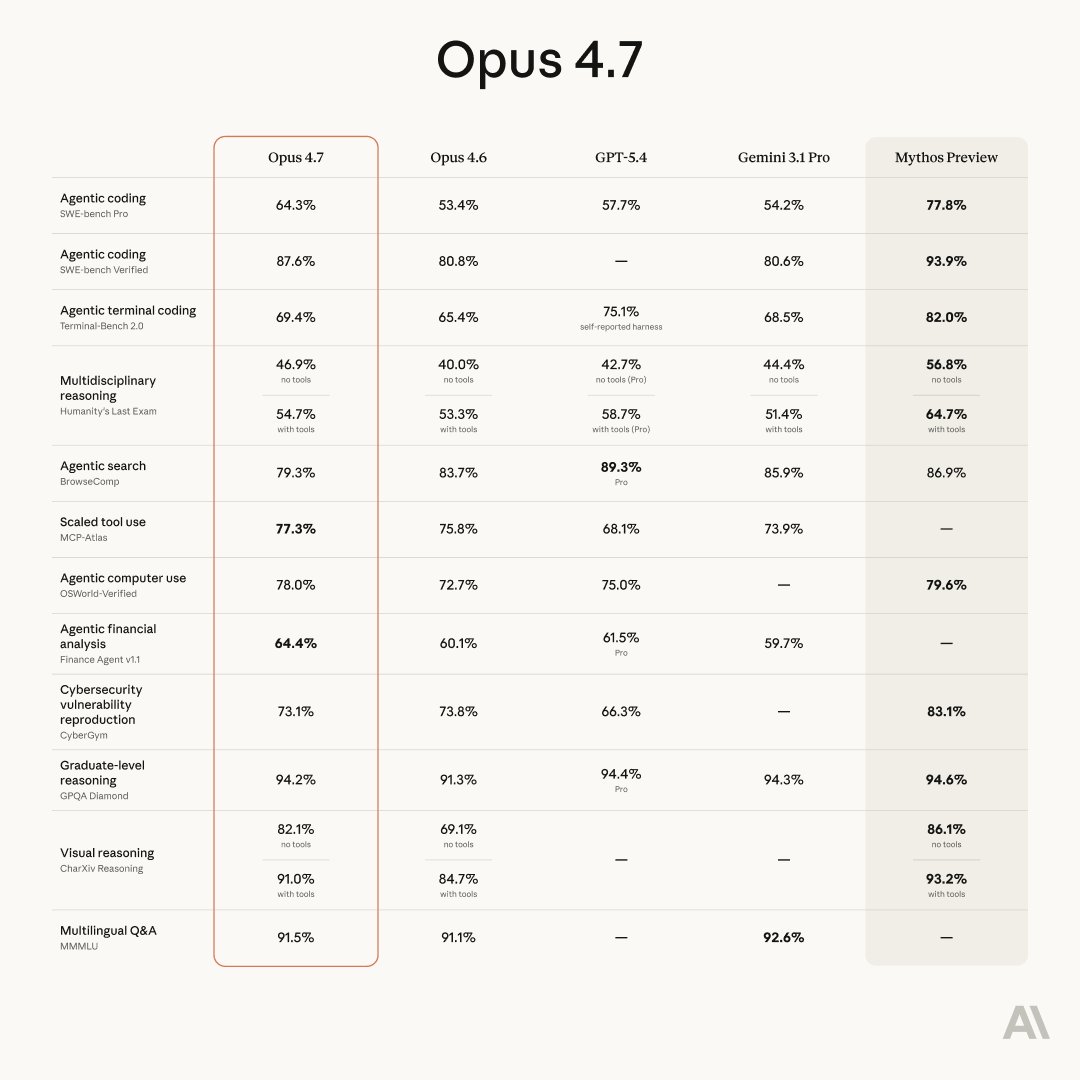 Figure: Claude Opus 4.7 benchmark performance across key metrics including SWE-bench Verified, Arena Elo, and agentic capabilities. Data from April 2026 evaluations.
Figure: Claude Opus 4.7 benchmark performance across key metrics including SWE-bench Verified, Arena Elo, and agentic capabilities. Data from April 2026 evaluations.
What Opus 4.7 Is Not: The Mythos Situation
Every article covering this release needs to address Claude Mythos (Capybara) directly, because the confusion between the two models is widespread.
Claude Opus 4.7 is Anthropic's commercial flagship. It is available to all users, all tiers, all API customers today.
Claude Mythos is a separate model in a new tier above Opus, confirmed by the March 2026 data store leak. Anthropic has described it as their most capable model to date, with cybersecurity capabilities that required a phased early-access rollout before broad availability. It remains under controlled access through Project Glasswing, with a public unveiling planned for May 2026 in San Francisco.
Opus 4.7 did not "replace" Mythos. They are on separate tracks. The commercial Opus line continues on its incremental cadence. Mythos is a capability breakthrough being released on a separate, safety-gated timeline. When Mythos goes public, it will occupy a new tier above Opus entirely, most likely branded separately from the Opus numbering system.
Migration Guide: Opus 4.6 to Opus 4.7
The migration is straightforward. Anthropic has maintained full API compatibility across the 4.x generation.
Step 1: Update the model string.
Replace claude-opus-4-6-20260205 with claude-opus-4-7-20260416 in your API calls, SDK configuration, or environment variables.
Step 2: Test in a staging environment. For agentic workflows and multi-step pipelines, run a sample of your production test cases against 4.7 before switching production traffic. Improved reasoning can occasionally produce different (usually better) tool call sequences for complex tasks.
Step 3: Update any hardcoded date strings. If you reference the model version date in your code or prompts, update them.
Step 4: Evaluate Routines if you have scheduled or event-driven workflows. Any workflow you currently trigger manually or via a cron job external to Claude is a candidate for migration to the Routines feature. The improvement in reliability for long-running autonomous sessions makes this worth evaluating.
Step 5: Consider the Advisor Tool for cost optimization. If you run high-volume workloads where Opus quality matters for complex reasoning but most requests are straightforward, the Advisor Tool pattern (Haiku executor, Opus 4.7 advisor) can maintain quality at significantly lower blended per-task cost.
What Comes Next
Sonnet 4.8 was confirmed in the Claude Code source code leak of March 31, 2026, where it appeared in the Undercover Mode forbidden version strings alongside Opus 4.7. Based on Anthropic's current six to eight week cadence, Sonnet 4.8 is likely four to six weeks out from today.
Beyond that, the Claude 4.x generation will eventually give way to Claude 5 and the arrival of Mythos at the commercial tier. Anthropic's October 2026 IPO timeline creates strong commercial pressure to ship Mythos in a form that demonstrates its capabilities publicly before the company goes to market. May's San Francisco announcement is the most concrete signal we have for that timeline.
Compare Claude Opus 4.7 Against Other Models
If you want to see how Opus 4.7 stacks up against GPT-5.4, Gemini 3.1 Pro, Qwen 3.5, and the other April 2026 frontier models across benchmarks, pricing, and context windows, our tools directory has everything in one place.
Compare AI models side by side on Renovate QR
The /tools directory covers every model referenced in this article with benchmark scores, API pricing, context windows, and deployment notes updated as new releases land.
Last updated: April 16, 2026. We will update this article as Anthropic publishes official benchmark data and as community evaluations emerge.
Frequently Asked Questions
What is Claude Opus 4.7?
Claude Opus 4.7 is Anthropic's new flagship model, released April 16, 2026. It is the successor to Claude Opus 4.6, which launched on February 5, 2026. Opus 4.7 focuses on improvements in multi-step reasoning, autonomous long-running task execution, multi-agent orchestration, and safety alignment. It retains the 1 million token context window from 4.6 and is expected to maintain the same pricing tier of $5.00 per million input tokens and $25.00 per million output tokens. It is available through the Anthropic API, AWS Bedrock, and Google Vertex AI.
What is the model string for Claude Opus 4.7?
The model string is claude-opus-4-7-20260416. As with all Claude models, Anthropic also provides a convenience alias claude-opus-4-7-latest that always points to the most recent Opus 4.7 patch. For production workloads, Anthropic recommends pinning to the dated version string to prevent unexpected behavior changes from patch updates. The model is available on Anthropic's API, AWS Bedrock (with both global and regional endpoints), and Google Vertex AI (with global, multi-region, and regional endpoints).
How does Claude Opus 4.7 differ from Opus 4.6?
Opus 4.7 is an incremental upgrade rather than a generational leap. The primary improvements are in multi-step reasoning depth, stability in autonomous long-running sessions, and multi-agent orchestration reliability. The model also ships with more extensive red-teaming coverage, better calibration on uncertainty (it is more likely to say it does not know rather than confabulate), and tighter prompt injection resistance for agentic deployments. Pricing, context window, and API interface remain the same, meaning migration from Opus 4.6 to 4.7 requires only a model string update.
Is Claude Opus 4.7 the same as Claude Mythos?
No. Opus 4.7 is a commercial flagship model available to all API users and Claude Pro/Max/Team/Enterprise subscribers. Claude Mythos, internally codenamed Capybara, is a separate model in a new tier above Opus, currently under controlled early access via Project Glasswing. Anthropic has described Mythos as far more powerful than any current commercial model and has delayed its broad release due to cybersecurity capability concerns. The public unveiling of Mythos is currently planned for May 2026 in San Francisco.
What is the Routines feature in Claude Opus 4.7?
Routines is a new capability that ships alongside Opus 4.7 in Claude Code and via the API. It allows developers to configure automated workflows that Claude triggers on a schedule, on GitHub events (such as a pull request or push to main), or via an API call. Example use cases include nightly bug triage runs across a codebase, automated PR reviews triggered on each commit, and recurring data analysis jobs. Routines effectively turn Claude into a persistent cloud-based software agent rather than a request-response tool. This is one of the most significant agentic capability expansions Anthropic has shipped.
What is the Advisor Tool beta in the Anthropic API?
The Advisor Tool is a new API feature launched alongside Opus 4.7. It pairs a fast executor model with a higher-intelligence advisor model that provides strategic guidance mid-generation, so long-horizon agentic workloads get close to advisor-only quality while the bulk of token generation happens at executor-model rates. Include the beta header advisor-tool-2026-03-01 in your API requests to enable it. The recommended pairing is Haiku 4.5 as executor and Opus 4.7 as advisor.
How do I migrate from Claude Opus 4.6 to Opus 4.7?
The migration is minimal. Update your model string from claude-opus-4-6-20260205 to claude-opus-4-7-20260416. The API interface, tool use schema, function calling format, and system prompt structure are fully compatible between versions. Anthropic recommends testing in a non-production environment first, particularly for agentic and multi-step workflows, as improved reasoning can occasionally produce different tool call sequences for the same task. Prompts written for Opus 4.6 work directly with Opus 4.7 without modification in the large majority of cases.
Will Claude Opus 4.6 be deprecated?
Anthropic has not announced a deprecation timeline for Opus 4.6 as of April 16, 2026. Based on past Anthropic deprecation patterns, Opus 4.6 will likely remain available for several months after the release of 4.7 before a retirement date is set. Anthropic typically provides 60 to 90 days notice before model retirement, as it did when deprecating Claude Sonnet 4 and Claude Opus 4 with a June 15, 2026 retirement date.

